深度学习面试题集(完善版)
本文档系统整理深度学习领域的常见面试问题与基础知识,覆盖七大核心模块共约 100 个子问题。每个问题都配有详尽的概念解释、数学推导、对比表格与示意图,力求做到"看完一篇就能搞懂一个主题"。适合面试准备、自学复习与日常查阅。
—— 文档结构 ——
- 第一章 神经网络:激活函数、梯度问题、正则化、BN、优化器、调参(33 个子问题)
- 第二章 卷积神经网络(CNN):经典网络、卷积运算、池化、变体(23 个子问题)
- 第三章 循环神经网络(RNN):训练特点、梯度消失、Keras 实现(6 个子问题)
- 第四章 LSTM:结构推导、门控机制、双向 LSTM、GRU 对比(7 个子问题)
- 第五章 反向传播:定义、原理、手推 BP(4 个子问题)
- 第六章 生成对抗网络(GAN):生成器、判别器、训练技巧(3 大节)
- 第七章 超参数调整:超参数列表、调优策略、预训练微调、自动搜索(6 大节)
一、神经网络基础
本章涵盖神经网络的基础概念:激活函数、初始化、归一化、正则化、优化器、损失函数等核心内容。这些是所有深度学习模型(CNN、RNN、Transformer)的共同基石。
1.1 各个激活函数的优缺点
激活函数为神经网络引入非线性,使其能够拟合任意复杂函数。若没有非线性激活,无论叠加多少层,整个网络仍等价于一个线性变换。
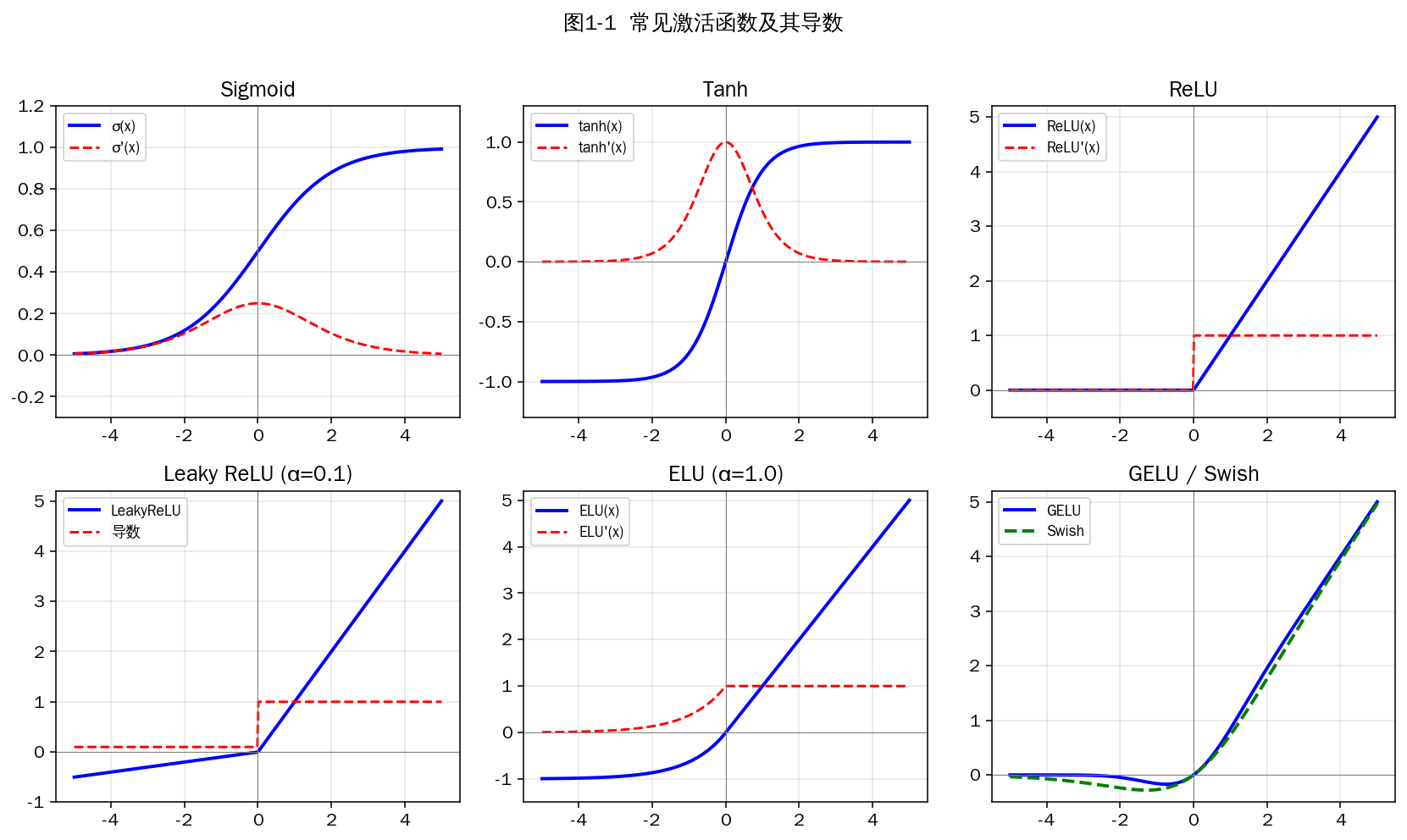
图1-1 常见激活函数及其导数(蓝色为函数本身,红色虚线为导数)
Sigmoid
σ(x) = 1 / (1 + e^(-x)), σ'(x) = σ(x)(1 - σ(x))
优点:
- 输出在 (0, 1) 之间,可直接解释为概率,常用于二分类输出层。
- 函数处处连续可导,便于反向传播。
缺点:
- 梯度消失:当 |x| 较大时 σ'(x) → 0,深层网络反向传播时梯度被压缩到极小(最大值仅为 0.25)。
- 输出非零均值:所有激活值恒为正,导致反向传播中权重梯度始终同号,参数更新呈"之"字形震荡。
- exp 运算计算开销较大。
Tanh(双曲正切)
tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x)), tanh'(x) = 1 - tanh²(x)
优点:
- 输出在 (-1, 1) 之间,零均值,缓解了 Sigmoid 的偏移问题,收敛速度更快。
- 导数最大值为 1(在 x=0 处),梯度大于 Sigmoid。
缺点:
- 仍存在饱和区与梯度消失问题(|x| 较大时导数趋零)。
- 计算量与 Sigmoid 相当。
ReLU(线性整流单元)
ReLU(x) = max(0, x)
优点:
- 计算极快,仅一次比较运算。
- 正区间梯度恒为 1,有效缓解梯度消失。
- 生物学合理性:让神经元具有稀疏激活的特性。
缺点:
- Dead ReLU 问题:若某神经元的预激活长期为负,则其梯度恒为 0,该神经元永远无法被激活更新。常见于学习率过大或初始化不当时。
- 输出非零均值。
- 在 x=0 处不可导(但实际工程中将其约定为 0 或 1)。
Leaky ReLU / PReLU / RReLU
LeakyReLU(x) = x if x > 0 else αx (α 通常取 0.01)
为负区间引入一个小斜率,缓解 Dead ReLU。
- Leaky ReLU:α 固定为小常数(0.01)。
- PReLU:α 作为可学习参数,由网络自行训练。
- RReLU:α 在训练时从均匀分布随机采样,测试时取期望。
ELU / SELU
ELU(x) = x if x > 0 else α(e^x - 1)
负区间用指数曲线平滑过渡,输出均值更接近 0;SELU 在 ELU 基础上加自归一化系数,理论上可让深层网络自我维持零均值单位方差。
GELU / Swish
GELU(x) = x · Φ(x), Swish(x) = x · σ(βx)
GELU 已成为 Transformer / BERT 的事实标准激活;Swish 由 Google 通过自动搜索得到,在多数 CNN 任务上略优于 ReLU。两者共同特点:平滑、非单调、允许小幅负值通过,组合了门控思想。
1.2 为什么 ReLU 常用于神经网络的激活函数
- 缓解梯度消失:正区间梯度恒为 1,深层网络仍能保持梯度量级,使得训练 50 层以上的网络成为可能。
- 计算高效:相比 Sigmoid/Tanh 的指数运算,ReLU 仅需一次阈值比较,前向和反向都极快。
- 稀疏激活:约 50% 的神经元输出为 0,类似生物神经元的稀疏激发模式,提升表示效率并具备一定正则效果。
- 单边抑制:负输入直接归零,模型对噪声更鲁棒。
- 实践有效性:从 AlexNet(2012)以来,几乎所有 SOTA 视觉模型都默认使用 ReLU 或其变体。
💡 提示: ReLU 不是"完美"的——在 Transformer 等架构上 GELU 已取而代之。但作为通用默认值,ReLU 在工程上仍是最稳妥的选择。
1.3 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?
在深层网络的反向传播中,梯度需要经过多层连乘。若每层梯度 < 1,相乘后趋向 0(梯度消失);若每层梯度 > 1,相乘后趋向无穷(梯度爆炸)。
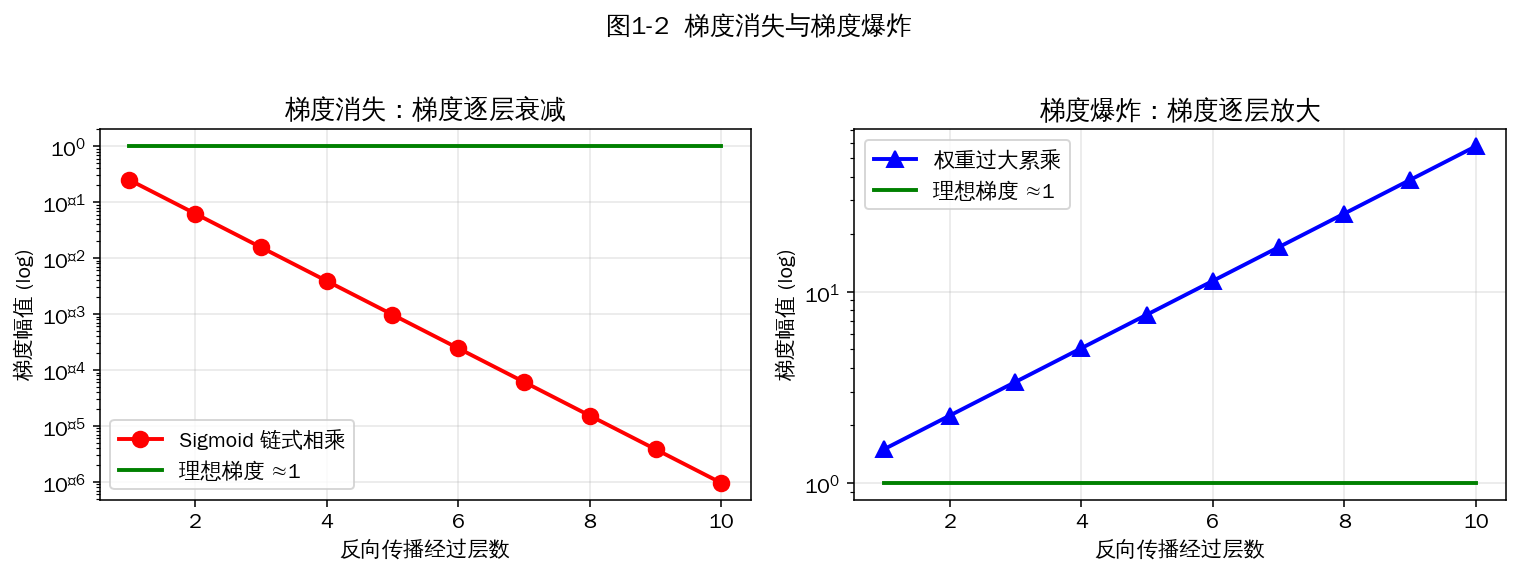
图1-2 Sigmoid 链式相乘导致梯度指数衰减;权重过大则梯度指数放大
梯度消失的解决方案:
- 使用 ReLU 系列激活函数替换 Sigmoid/Tanh。
- Batch Normalization:将每层激活拉回标准分布,避免落入饱和区。
- 残差连接(ResNet):通过 y = F(x) + x 提供恒等映射,让梯度可直接回传到浅层。
- 合理初始化:He / Xavier 初始化使每层激活的方差保持稳定。
- LSTM/GRU:通过门控机制为 RNN 提供"梯度高速公路"。
梯度爆炸的解决方案:
- 梯度裁剪(Gradient Clipping):限制梯度的范数上限,是 RNN 训练的标配。
- 权重正则化(L1/L2):约束权重不会变得过大。
- 合理初始化 + BN。
- 使用较小的学习率。
梯度爆炸引发的问题:
- 损失出现 NaN/Inf,训练崩溃。
- 权重更新步长过大,越过最优点,损失剧烈震荡。
- 模型完全失效,需重新训练。
1.4 如何确定是否出现梯度爆炸
- 损失值变为 NaN 或 Inf。
- 损失函数曲线剧烈震荡,无法收敛。
- 梯度范数(torch.nn.utils.clip_grad_norm_ 的返回值)持续 > 1e2 或 1e3。
- 权重值在训练过程中迅速变大,甚至溢出。
- 模型预测全部输出极端值(如全 1 或全 0)。
监控做法:训练时打印 grad_norm 与 weight_norm;TensorBoard 中观察每层的梯度直方图。
1.5 神经网络中有哪些正则化技术
正则化用于防止过拟合,让模型在测试集上的表现更好。
类别 | 方法 | 原理 |
参数约束 | L1 正则化 | 在损失中加入 λ‖w‖₁,促使权重稀疏,可做特征选择 |
参数约束 | L2 正则化(权重衰减) | 在损失中加入 λ‖w‖₂²,抑制权重过大,使决策面平滑 |
网络结构 | Dropout | 训练时随机让神经元失活,相当于集成大量子网络 |
网络结构 | DropConnect | 随机将连接的权重置零,比 Dropout 更细粒度 |
归一化 | BN / LN / GN | 约束每层激活的分布,间接起到正则作用 |
数据 | 数据增强 | 旋转、翻转、裁剪、Mixup、CutMix 等扩充训练分布 |
训练 | Early Stopping | 验证集 loss 不再下降时停止训练 |
训练 | 标签平滑(Label Smoothing) | 将 one-hot 标签替换为 1-ε 和 ε/(K-1),防止过度自信 |
训练 | 权重平均(EMA / SWA) | 对训练后期的权重做指数移动平均,提升泛化 |
1.6 批量归一化(BN)如何实现?作用?
BN 由 Sergey Ioffe 在 2015 年提出,是深度学习训练最重要的技巧之一。
实现步骤(对每个 mini-batch 的某一层激活):
μ_B = (1/m) Σ x_i
σ²_B = (1/m) Σ (x_i - μ_B)²
x̂_i = (x_i - μ_B) / sqrt(σ²_B + ε)
y_i = γ · x̂_i + β (γ, β 为可学习的尺度和偏移参数)
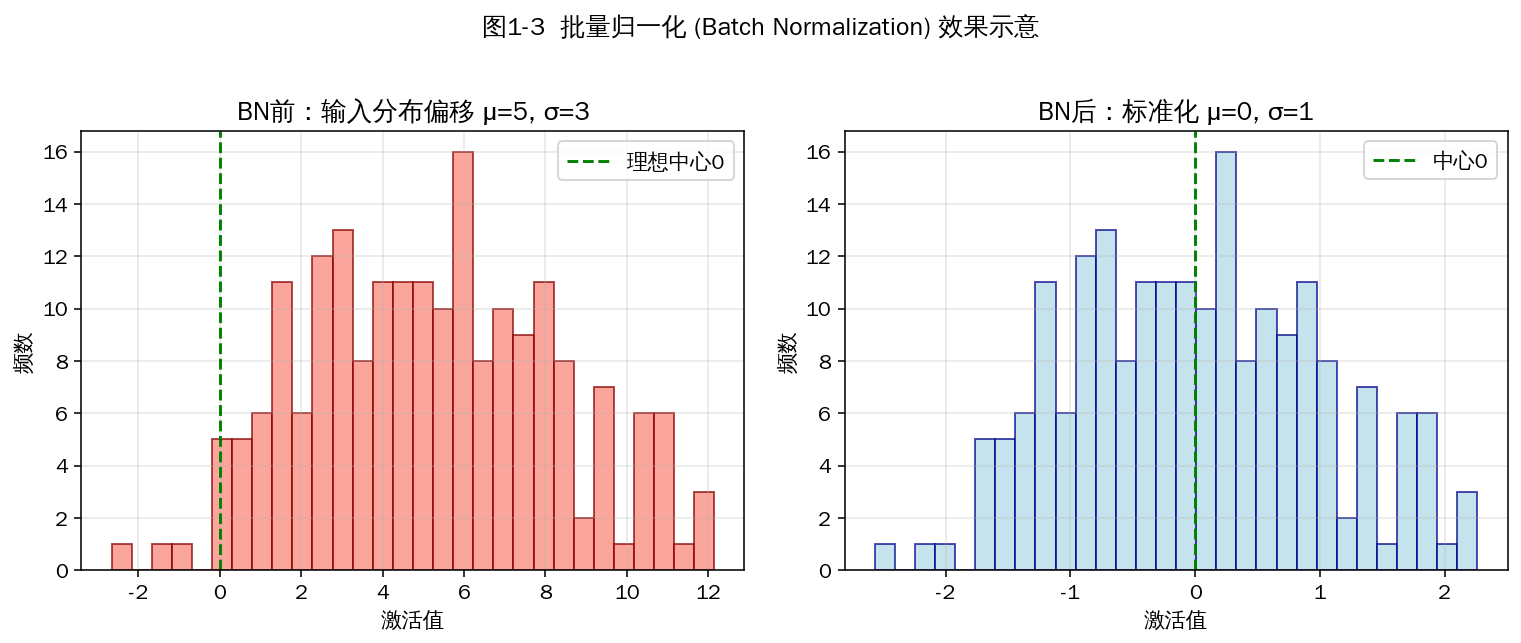
图1-3 BN 将激活分布标准化到 0 均值、单位方差
作用:
- 加速收敛:允许使用更大的学习率,训练时间常缩短 5~10 倍。
- 缓解梯度消失:将激活拉回非饱和区。
- 一定的正则化效果:mini-batch 统计噪声相当于轻度数据增强,常可减少 Dropout 用量。
- 降低对初始化的敏感度。
注意:测试阶段用整个训练集的运行均值(running mean)和运行方差代替 mini-batch 统计量。
1.7 神经网络中权值共享的理解
"权值共享"指同一组参数被网络中多个位置或多个时间步重复使用。
典型场景:
- CNN:同一个卷积核滑过整张特征图,所有位置共用一组权重。原因:自然图像的局部特征(边缘、纹理)具有平移不变性,无论目标出现在图像哪个位置,都应被同一组检测器识别。
- RNN:所有时间步共用同一个权重矩阵 W_hh 与 W_xh。原因:序列数据的语法/语义规则不应依赖于绝对时间位置。
优点:
- 大幅减少参数量。例如 224×224 图像若用全连接需上亿参数,用 CNN 可降到百万级。
- 提供归纳偏置(inductive bias),使网络在小数据集上也能泛化。
- 使模型具备平移不变性 / 时间不变性。
1.8 对 fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值
Fine-tuning 是迁移学习的核心做法:先用大数据集(如 ImageNet)预训练得到通用特征提取器,再在目标小数据集上继续训练。
为什么修改最后几层:
- 底层卷积学到的是低级通用特征(边缘、纹理、颜色),这些特征跨数据集通用,不需要重新学习。
- 高层(特别是分类头)学到的是任务相关的高级语义。新任务的类别空间不同,因此最后一层必须替换并重新训练。
- 小数据集上从头训练深网络极易过拟合,仅微调顶层可大幅缓解。
1.9 什么是 Dropout?为什么有用?它是如何工作的
Dropout 由 Hinton 在 2012 年提出:训练时以概率 p 随机将神经元的输出置零,测试时使用全部神经元(但需缩放)。
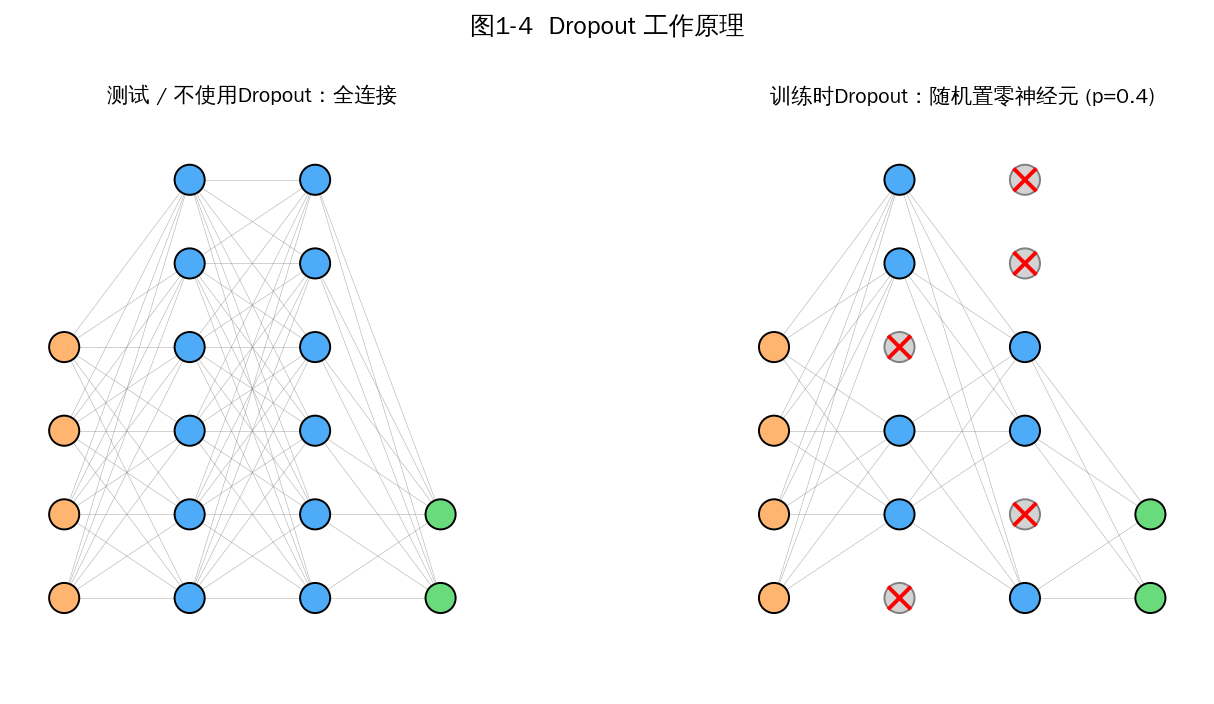
图1-4 训练时随机失活神经元;测试时使用完整网络
工作原理:
- 训练时:每个 mini-batch 前,对每个隐层神经元独立地以概率 p 置零,反向传播只更新未被丢弃的连接。
- 测试时(Inverted Dropout 实现):所有神经元都保留,但训练时输出已按 1/(1-p) 放大,因此测试时直接使用即可。
为什么有用:
- 集成视角:每次 mini-batch 都相当于训练一个不同的"子网络",共享权重。最终模型相当于 2^N 个子模型的几何平均集成。
- 打破协同适应:神经元不能依赖某个固定的"队友",被迫学习更鲁棒的特征。
- 增加输入噪声:相当于一种自适应的噪声注入。
1.10 如何选择 dropout 的概率
- 输入层:通常 p=0.1~0.2(不能丢太多原始信息)。
- 隐藏层:经典取值 p=0.5(Hinton 论文推荐);现代网络配合 BN 后常用 0.1~0.3。
- 卷积层:很少使用普通 Dropout(卷积特征空间相关性强),改用 Spatial Dropout(整通道丢弃)或 DropBlock(连续区域丢弃)。
- 调参建议:模型容量大、过拟合严重时调高;模型欠拟合时调低或去掉。
1.11 什么是 Adam?Adam 和 SGD 之间的主要区别
Adam(Adaptive Moment Estimation)由 Kingma 在 2014 年提出,结合了 Momentum(一阶矩)和 RMSProp(二阶矩)的思想。
Adam 的更新规则:
m_t = β₁·m_{t-1} + (1-β₁)·g_t (一阶矩, 类似动量)
v_t = β₂·v_{t-1} + (1-β₂)·g_t² (二阶矩, 梯度平方)
m̂_t = m_t / (1 - β₁^t), v̂_t = v_t / (1 - β₂^t) (偏差修正)
θ_t = θ_{t-1} - lr · m̂_t / (sqrt(v̂_t) + ε)
默认超参:β₁=0.9, β₂=0.999, ε=1e-8。
Adam 与 SGD 的主要区别:
对比维度 | SGD(含 Momentum) | Adam |
学习率 | 全局统一 | 每个参数自适应 |
一阶矩 | Momentum 维护 | 维护并做偏差修正 |
二阶矩(梯度平方) | 不维护 | 维护,用于缩放学习率 |
收敛速度 | 前期慢,需精细调参 | 快,对初值不敏感 |
泛化能力 | 常常更好(尤其CV任务) | 可能略差,可能陷入尖锐极小 |
内存开销 | 存 1 份动量 | 存 2 份矩估计 |
典型场景 | ImageNet 分类、检测 | NLP、GAN、小数据集快速实验 |
1.12 为什么 Momentum 可以加速训练
v_t = γ·v_{t-1} + (1-γ)·g_t θ_t = θ_{t-1} - lr · v_t
Momentum 引入物理学中的"动量"概念:当前更新方向不是当前梯度,而是历史梯度的加权累积。γ 通常取 0.9。
加速原理:
- 在梯度方向一致的维度上(如长椭圆谷底的长轴方向),累积速度逐步加快,相当于动态放大学习率。
- 在梯度方向反复振荡的维度上(短轴方向),正负相消,抑制震荡。
- 帮助跨越平坦区域和小局部极小值(凭借惯性"冲过去")。
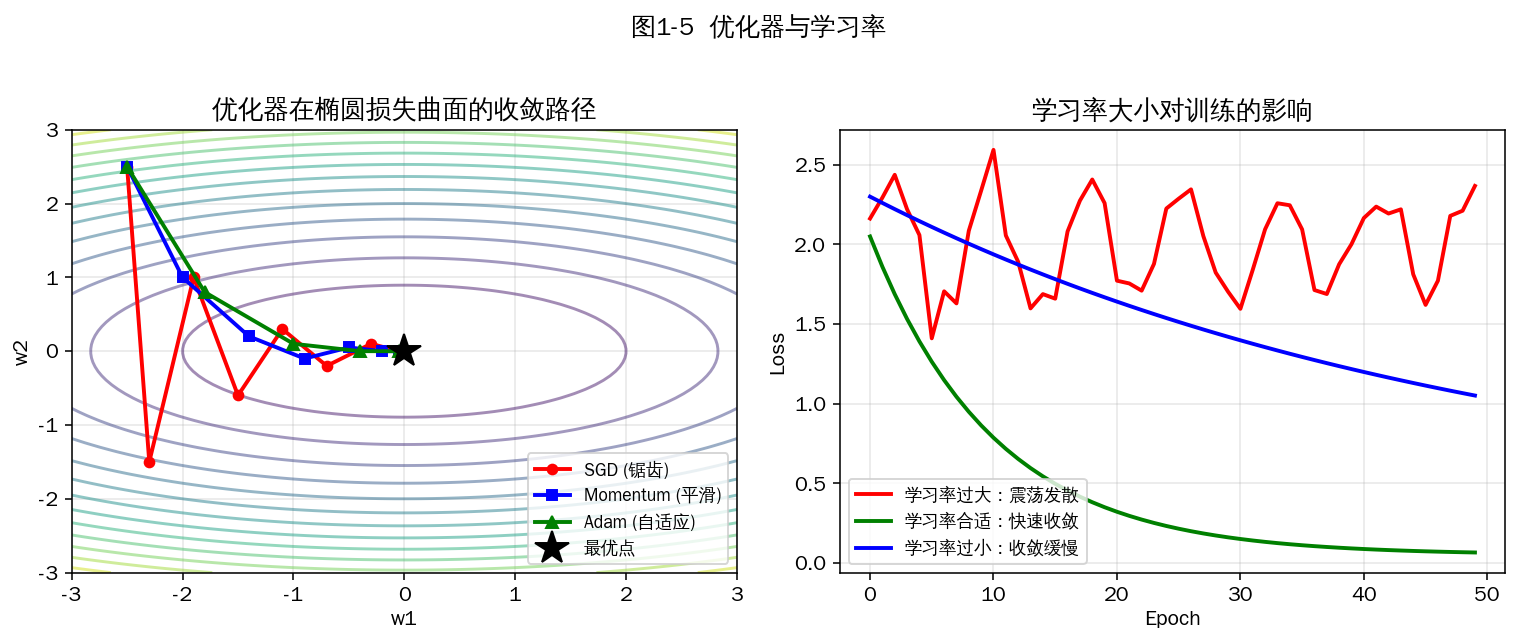
图1-5 优化器收敛路径对比(左);学习率影响(右)
1.13 什么时候使用 Adam 和 SGD
Adam 适用场景:
- 快速原型验证:默认参数即可获得不错结果。
- NLP 任务(Transformer、BERT 微调等)。
- GAN、强化学习等损失非凸且复杂的场景。
- 数据稀疏(不同特征出现频率差异巨大)的场景。
SGD(Momentum / Nesterov)适用场景:
- 对最终精度有极致要求的视觉任务(ImageNet 分类、COCO 检测)。
- 需要精细控制收敛过程、配合学习率调度。
- 追求最优泛化能力,避免 Adam 陷入"尖锐极小"。
实践折中:先用 Adam 快速训练若干 epoch,后期切换到 SGD 微调,常获两者之长。
1.14 batch size 和 epoch 的平衡
batch size:每次梯度更新所用样本数。epoch:整个训练集被遍历一次。
batch size 的影响:
- 较大:梯度估计准,单步更新稳定,GPU 利用率高;但内存压力大、可能陷入尖锐极小、泛化变差。
- 较小:梯度有噪声(隐式正则),泛化可能更好;但训练慢、不稳定。
经验法则:
- 线性缩放规则(Goyal et al., 2017):batch size 加倍时学习率也加倍,可在 ImageNet 上保持收敛性。
- 视觉任务常用 batch size 256;大模型预训练动辄数千甚至数万(配合梯度累积)。
- 小数据集(<10k 样本)batch size 取 16~64。
1.15 SGD 每步做什么,为什么能 online learning
SGD 每步:
- 从训练集中采样一个(或一小批)样本。
- 前向计算损失。
- 反向传播得到梯度 g。
- 更新参数:θ ← θ - lr · g。
为什么支持 online learning:
online learning 指数据按时间顺序到达,每次到一个样本就用它更新模型。SGD 本身的"每次一个样本(或一小批)"的更新机制天然契合这种场景——无需保留全部历史数据,可以边到达边学习。批量梯度下降(BGD)需要遍历全部样本才能更新一次,无法做 online。
1.16 学习率太大(太小)时会发生什么?如何设置学习率
学习率太大:
- 损失剧烈震荡,甚至发散到 NaN。
- 在最优点附近来回跳,无法精确收敛。
- 梯度爆炸风险增加。
学习率太小:
- 收敛速度极慢,训练时间不可接受。
- 容易陷入糟糕的局部极小值或鞍点。
如何设置学习率:
- LR Range Test(Smith, 2017):从极小学习率开始,每个 batch 指数式增大,绘制 loss-lr 曲线,选择 loss 下降最快段对应的学习率作为最大值。
- Warmup:训练初期用极小学习率(避免参数被错误大梯度带偏),然后线性升至目标值,再衰减。
- 调度策略:Step Decay、Cosine Annealing、Cyclical LR、ReduceLROnPlateau 等。
- 参考默认:Adam 常用 1e-3 ~ 1e-4;SGD+Momentum 常用 0.1 ~ 0.01(视觉分类)。
1.17 神经网络为什么不用拟牛顿法而是用梯度下降
牛顿法用二阶导数信息(Hessian 矩阵)寻找极值,理论上收敛更快(二次收敛)。但在深度学习中几乎不用,原因:
- Hessian 计算/存储代价巨大:参数量为 N,Hessian 为 N×N,深度模型 N ≥ 10⁷,根本无法存储更别提求逆。
- 非凸性:神经网络损失曲面有大量鞍点和局部极小,Hessian 不一定正定,牛顿法可能朝错误方向更新。
- mini-batch 噪声:Hessian 估计噪声大于梯度,得不偿失。
- 一阶方法+自适应+动量已经足够好:Adam、SGD+Momentum 在实践中收敛速度和泛化都已经令人满意。
拟牛顿法(如 L-BFGS)在凸优化、小参数模型上仍有应用,但深度网络主流仍是一阶方法。
1.18 BN 和 Dropout 在训练和测试时的差别
训练时 | 测试时 | |
BN | 使用当前 mini-batch 的均值/方差归一化,并更新运行均值/方差 | 使用累积的运行均值/方差归一化(固定值) |
Dropout | 以概率 p 随机失活神经元,输出按 1/(1-p) 放大(Inverted) | 所有神经元都保留,不做任何随机操作 |
⚠️ 注意: PyTorch 中调用 model.eval() 即可切换 BN/Dropout 到测试模式,调用 model.train() 切回训练模式。常见 bug:忘记 eval() 导致测试结果异常。
1.19 若网络初始化为 0 的话有什么问题
全零初始化导致对称性问题(symmetry problem):
- 每个神经元接收相同输入、产生相同输出。
- 反向传播时每个神经元接收相同梯度,更新后权重仍然完全相同。
- 整层神经元始终保持完全一致,相当于只有一个神经元在工作。
因此必须用随机初始化打破对称性。常用方案:Xavier(适合 Tanh/Sigmoid)、He/Kaiming(适合 ReLU 系)。偏置 b 可以初始化为 0,因为对称性已由权重打破。
1.20 sigmoid 和 softmax 的区别?softmax 的公式
sigmoid: σ(x) = 1 / (1 + e^(-x)) [输入一个标量,输出一个概率]
softmax: softmax(x)_i = e^(x_i) / Σ_j e^(x_j) [输入向量,输出概率分布]
区别:
Sigmoid | Softmax | |
输入 | 单个标量 | 向量(K维) |
输出 | 一个 (0,1) 概率 | K 维概率分布,和为 1 |
用途 | 二分类 / 多标签分类 | 互斥的多分类 |
类别独立性 | 各输出相互独立 | 各输出之间相互竞争(总和约束为 1) |
📌 备注: 特例:K=2 的 Softmax 与 Sigmoid 在数学上等价(只差一个常数偏置)。
1.21 改进的 softmax 损失函数有哪些
改进主要针对人脸识别等"类间距离"敏感任务:让同类样本更紧凑,不同类样本更分离。
- L-Softmax(Large-Margin Softmax):在角度 θ 上引入乘性间隔 m,要求 cos(mθ) 才能正确分类。
- A-Softmax / SphereFace:将权重归一化到单位球面上,直接学习角度判别。
- AM-Softmax(CosFace):在余弦相似度上做加法间隔,cos(θ) - m。
- ArcFace:在角度上加加法间隔,cos(θ + m),几何意义清晰,是人脸识别 SOTA。
- Focal Loss(Lin et al., 2017):解决类别不均衡,对易分类样本降权 (1-p)^γ。
- Label Smoothing:将硬标签 [0,0,1,0] 改为 [ε/K, ε/K, 1-ε, ε/K],缓解过度自信。
1.22 深度学习调参有哪些技巧
- 先过拟合一个小子集(如 100 样本),验证模型实现正确。
- 从已知有效的 baseline 出发,单次只改一个超参数。
- 学习率优先调:LR Range Test → 选最佳值 → 配合 warmup + cosine 衰减。
- batch size 尽量大(在显存允许范围内),相应放大学习率。
- 用 Adam 快速验证想法,最终用 SGD+Momentum 拿到最佳数值。
- weight decay 通常 1e-4 ~ 5e-4(视觉任务);Adam 应使用 AdamW 的解耦权重衰减。
- 数据增强是免费的精度提升:CV 用 RandAugment/MixUp/CutMix;NLP 用 BackTranslation。
- 用 TensorBoard / Weights & Biases 监控 loss、accuracy、梯度范数、权重直方图。
- 混合精度训练(fp16/bf16)可省一半显存并加速 1.5~2 倍。
- 随机种子固定,便于复现实验。
1.23 神经网络调参,要往哪些方向想
遇到训练问题时,按照如下决策树排查:
- Loss 不下降 → 学习率是否过小?数据/标签是否正确?模型结构是否能拟合?
- Loss 为 NaN → 学习率过大、数据中有 Inf、log(0)、除 0;先做梯度裁剪。
- 训练集精度低(欠拟合)→ 增大模型容量、训练更久、减小正则、检查数据。
- 训练集高、验证集低(过拟合)→ 加正则、加 Dropout、加数据增强、Early Stopping、降低模型容量。
- 训练集和验证集都低 → 改用更强 backbone、检查 label noise。
- 某些类别精度很差 → 类别不均衡,用 Focal Loss、过采样、Class-Balanced Loss。
1.24 深度学习训练中是否有必要使用 L1 获得稀疏解
L1 正则化(Lasso)会使部分权重严格变为 0,得到稀疏解;L2 正则化(Ridge)使权重整体变小但不为 0。
深度学习中是否需要 L1:
- 通常不需要:L2/weight decay 已经足够,且 Dropout、BN 也起到正则作用。
- 需要稀疏解的场景:模型剪枝(Network Pruning)、嵌入式部署、可解释性研究、特征选择。
- 实践中更常用的是结构化稀疏(如 group lasso、滤波器剪枝)而不是逐参数 L1。
1.25 神经网络数据预处理方法有哪些?中心化/零均值,归一化
零中心化(Zero-Centering):减去均值,使数据中心在原点。
x = x - μ
归一化(Normalization):缩放到单位方差或 [0,1]。
Standardization: x = (x - μ) / σ
Min-Max: x = (x - x_min) / (x_max - x_min)
PCA / Whitening(白化):去除特征间相关性,使协方差矩阵为单位阵。深度网络中已较少使用(BN 起到类似作用)。
图像任务的典型做法:
- ImageNet 模型:减去 RGB 通道均值 [0.485, 0.456, 0.406],除以方差 [0.229, 0.224, 0.225]。
- 或简单的 (x/255 - 0.5)/0.5 缩放到 [-1, 1]。
1.26 如何初始化神经网络的权重?神经网络怎样进行参数初始化
核心原则:保持各层激活的方差稳定,既不爆炸也不消失。
常见初始化方法:
方法 | 公式 | 适用激活 |
Xavier (Glorot) 均匀 | U(-sqrt(6/(n_in+n_out)), +sqrt(6/(n_in+n_out))) | Tanh, Sigmoid |
Xavier 正态 | N(0, 2/(n_in+n_out)) | Tanh, Sigmoid |
He (Kaiming) 正态 | N(0, 2/n_in) | ReLU, LeakyReLU |
He 均匀 | U(-sqrt(6/n_in), +sqrt(6/n_in)) | ReLU 系 |
Orthogonal | 使权重矩阵为正交阵 | RNN |
全 0 | — | 偏置 b(权重 W 不可) |
PyTorch 默认对 Linear/Conv2d 使用 Kaiming 均匀初始化。
1.27 为什么构建深度学习模型需要使用 GPU
- 大规模并行计算:神经网络的核心运算(矩阵乘法、卷积)天然可并行。CPU 有 8~64 核,GPU 有数千个 CUDA 核心。
- 高内存带宽:GPU HBM 显存带宽达 1 TB/s 以上,远高于 CPU 内存(约 50 GB/s)。
- 专用张量核(Tensor Core):从 Volta 开始的 NVIDIA GPU 配备 Tensor Core,对 fp16/bf16/int8 矩阵乘加做硬件加速。
- 深度学习框架成熟生态:CUDA + cuDNN + NCCL + 各种分布式训练库。
实测对比:ResNet-50 在 ImageNet 上训练一个 epoch,CPU 约需数小时,单卡 V100 约需 8 分钟,8 卡 A100 仅需 1 分钟。
1.28 前馈神经网络(FNN)、递归神经网络(RNN)和 CNN 的区别
模型 | 连接方式 | 关键特性 | 典型场景 |
FNN (MLP) | 层间全连接,无循环 | 参数最多,最通用 | 结构化表格数据、小规模分类 |
CNN | 局部连接 + 权值共享 | 平移不变性,处理网格数据 | 图像、视频、语音 |
RNN | 隐状态在时间维循环 | 处理变长序列,有时序记忆 | 文本、语音、时间序列 |
FNN 是基础形式;CNN 在 FNN 上加入空间归纳偏置(局部+共享);RNN 在 FNN 上加入时间维循环。Transformer 可视为对 RNN/CNN 的另一种归纳偏置选择(自注意力替代循环和卷积)。
1.29 神经网络可以解决哪些问题
- 分类(Classification):图像分类、文本分类、垃圾邮件检测。
- 回归(Regression):房价预测、传感器数值预测。
- 检测与定位(Detection):目标检测、语义分割、关键点检测。
- 生成(Generation):图像生成(GAN/Diffusion)、文本生成、语音合成。
- 序列建模:机器翻译、语音识别、问答系统。
- 决策与控制(RL):游戏 AI、机器人控制、推荐系统。
- 表示学习:自监督预训练得到通用 embedding,下游各类任务复用。
1.30 如何提高小型网络的精度
- 知识蒸馏(Knowledge Distillation):用大模型(Teacher)的软标签训练小模型(Student),让小模型继承大模型的"暗知识"。
- 数据增强(强增强):RandAugment、AutoAugment、MixUp、CutMix、Mosaic 等。
- 神经架构搜索(NAS):自动找到给定 FLOPs 预算下最优结构(如 MobileNetV3、EfficientNet)。
- 深度可分离卷积、Inverted Residual:以更少参数获得相近表达能力。
- 合理的正则化:Dropout、Stochastic Depth、Label Smoothing。
- 更长的训练 + 余弦学习率退火 + EMA 权重平均。
- 量化感知训练(QAT):让模型适应 int8 推理。
1.31 列举你所知道的神经网络中使用的损失函数
分类任务:
- 交叉熵损失(Cross-Entropy Loss):多分类标配。
- 二元交叉熵(Binary Cross-Entropy / BCE):二分类或多标签分类。
- Focal Loss:处理类别不均衡(如目标检测中前景/背景)。
- Hinge Loss:SVM 风格的最大间隔分类。
回归任务:
- L1 Loss / MAE:对异常值更鲁棒。
- L2 Loss / MSE:处处可导,常用。
- Smooth L1 / Huber Loss:L1 与 L2 的折中,Faster R-CNN 用于 bbox 回归。
度量学习:
- Triplet Loss:拉近正样本,推开负样本(人脸识别)。
- Contrastive Loss:对比学习的核心损失(SimCLR、MoCo)。
- InfoNCE:自监督学习中广泛使用。
分割与生成:
- Dice Loss / IoU Loss:医学图像分割。
- Perceptual Loss:基于 VGG 高层特征比较,用于图像生成。
- GAN Loss(原始 / WGAN / LSGAN):生成对抗。
1.32 什么是鞍点问题?梯度为 0,海森矩阵不定的点,不是极值点
鞍点定义:梯度 ∇L = 0,但 Hessian 矩阵 H 不定(既有正特征值又有负特征值)。在某些方向上是极小值,另一些方向上是极大值。
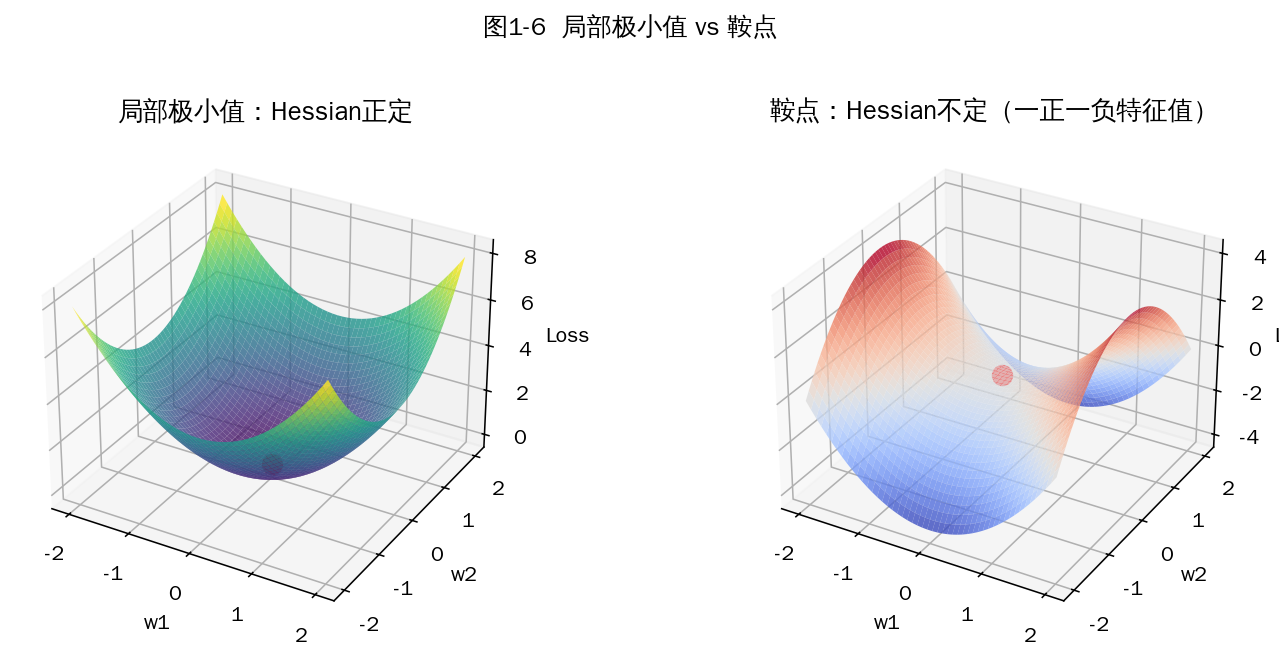
图1-6 局部极小值(左,Hessian 正定)vs 鞍点(右,Hessian 不定)
为什么鞍点在高维空间中比局部极小更常见:
在 N 维空间,Hessian 是 N×N 矩阵;要它正定需要 N 个特征值都为正(概率约 (1/2)^N)。N 越大,鞍点比例呈指数级增加,局部极小反而稀少(且常常接近全局最优)。
鞍点的危害:
- 梯度为 0,普通 SGD 容易停滞。
- 附近平坦区域(plateau)会让训练速度极慢。
对策:
- Momentum / Adam 的动量项可以"冲过"鞍点。
- mini-batch 的随机噪声本身有助于逃离鞍点。
- 合理初始化避开鞍点密集区。
1.33 网络设计中,为什么卷积核设计尺寸都是奇数
- 对称性 / 中心像素:奇数卷积核(3×3、5×5、7×7)有明确的几何中心,方便定位"以中心像素为锚点"的特征,padding 后特征图位置不偏移。
- Padding 对称:奇数 kernel 用 (kernel-1)/2 的 padding 即可保持输入输出尺寸相同;偶数 kernel 需要不对称 padding,会引入位置偏移。
- 感受野有偏:偶数卷积核的感受野中心落在两个像素中间,存在 0.5 像素偏移。
- 历史惯性:经典网络(LeNet、AlexNet、VGG、ResNet)全部采用奇数核,工程实现和优化都围绕奇数核展开。
例外:有些 1×1 卷积也常见,主要用于通道维变换(升降维),不涉及空间卷积。
二、卷积神经网络(CNN)
卷积神经网络是计算机视觉的基础架构。其核心思想是利用图像的空间结构特性——局部连接、权值共享、平移不变性——大幅减少参数量并提升泛化。本章覆盖 CNN 的结构、计算、经典网络(LeNet 到 DenseNet)和常见变体(1×1 卷积、空洞卷积、转置卷积等)。
2.1 卷积神经网络的结构
典型 CNN 由若干个"卷积-激活-池化"模块串联,最后接全连接层做分类。
核心组件:
- 卷积层(Convolutional Layer):用卷积核在输入特征图上滑动,做局部加权求和,提取空间特征。
- 激活函数(Activation):通常是 ReLU,引入非线性。
- 池化层(Pooling Layer):下采样,减小空间尺寸,扩大后续层的感受野,提供一定平移不变性。
- 全连接层(Fully-Connected, FC):将高维特征图展平后映射到类别空间。
- BN/Dropout/残差连接 等辅助组件。
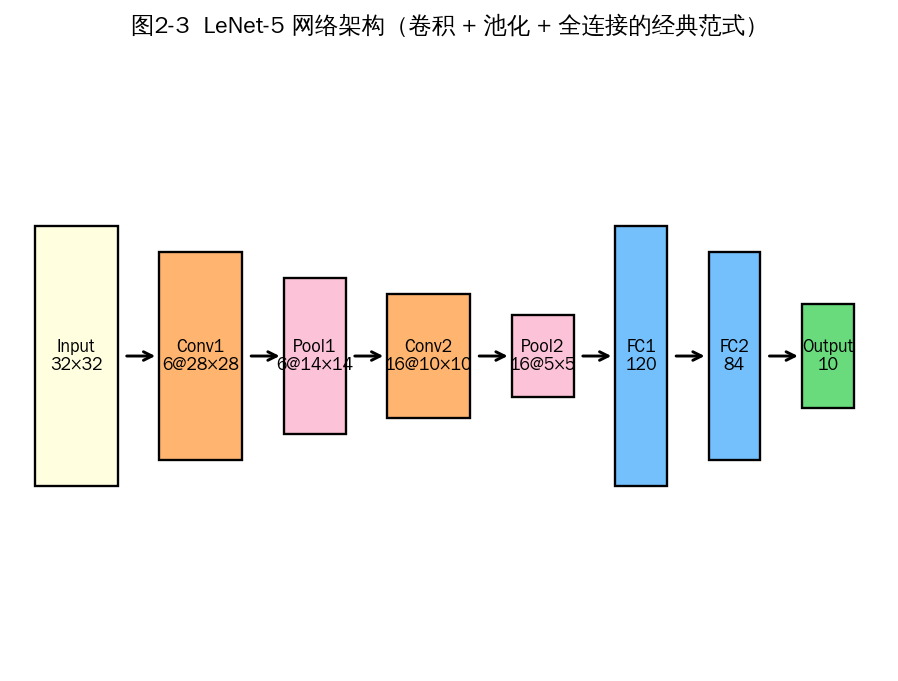
图2-3 LeNet-5 的层级结构(输入 → 多次"卷积+池化" → 全连接 → 输出)
2.2 Keras 搭建 CNN
一个用 Keras 搭建经典 CNN 的简洁示例(MNIST 风格的图像分类):
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', padding='same',
input_shape=(28, 28, 1)),
layers.BatchNormalization(),
layers.MaxPooling2D((2, 2)), # 28×28 → 14×14
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.BatchNormalization(),
layers.MaxPooling2D((2, 2)), # 14×14 → 7×7
layers.Conv2D(128, (3, 3), activation='relu', padding='same'),
layers.GlobalAveragePooling2D(), # 替代 Flatten + FC
layers.Dropout(0.3),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=128,
validation_data=(x_val, y_val))
2.2 经典网络分类
2.2.1 LeNet (1998, Yann LeCun)
- 世界上第一个成功的 CNN,用于手写数字识别(MNIST、邮政编码识别)。
- 结构:Conv(6, 5×5) → AvgPool → Conv(16, 5×5) → AvgPool → FC(120) → FC(84) → Output(10)。
- 激活函数用 Sigmoid/Tanh(当时还没有 ReLU),池化用平均池化。
- 约 6 万参数,奠定了"卷积+池化+全连接"的经典范式。
2.2.2 AlexNet (2012, Krizhevsky et al.)
- 深度学习"复兴"的标志性工作,ImageNet 2012 冠军,top-5 错误率从 26% 降到 15%。
- 8 层网络(5 卷积 + 3 全连接),约 6000 万参数。
- 首次大规模使用 ReLU 激活,解决深网梯度消失。
- 引入 Dropout 减轻过拟合。
- 在两块 GTX 580 GPU 上并行训练。
- 使用 LRN(局部响应归一化),后被 BN 取代。
2.2.3 VGG (2014, Simonyan & Zisserman)
- 提出"用堆叠的 3×3 卷积代替大卷积核"的思想,结构极简但深度更大(16/19 层)。
- 两个堆叠的 3×3 卷积的感受野等同于一个 5×5,但参数减少 28%,且引入两次非线性。
- 参数主要集中在最后三层全连接(约 1.2 亿),是计算量瓶颈。
- 结构清晰,迁移学习效果好,至今仍作为基线模型和感知损失的特征提取器。
2.2.4 Inception / GoogLeNet (2014, Szegedy et al.)
- 提出 Inception 模块:在同一层并行使用 1×1、3×3、5×5 卷积和池化,再拼接结果。
- 用 1×1 卷积做"瓶颈"降维,大幅减少计算量。
- 引入辅助分类器(auxiliary head),缓解深层梯度消失,训练时贡献额外梯度。
- 参数仅 500 万,远小于 VGG,但 ImageNet top-5 误差更低。
- 后续演进:Inception-V2/V3(分解大卷积为多个小卷积,引入 BN)、V4、Inception-ResNet。
2.2.5 ResNet (2015, He et al.)
- 提出残差连接(Residual Connection),解决"深网退化"问题(深网在训练集上误差更高)。
- 核心公式:y = F(x) + x。即使 F(x) 学到的是 0,整个块仍是恒等映射。
- 成功训练了 152 层网络,ImageNet 2015 冠军,top-5 误差 3.57%。
- 彻底改变了深度学习架构设计——之后所有大模型几乎都使用跳连。
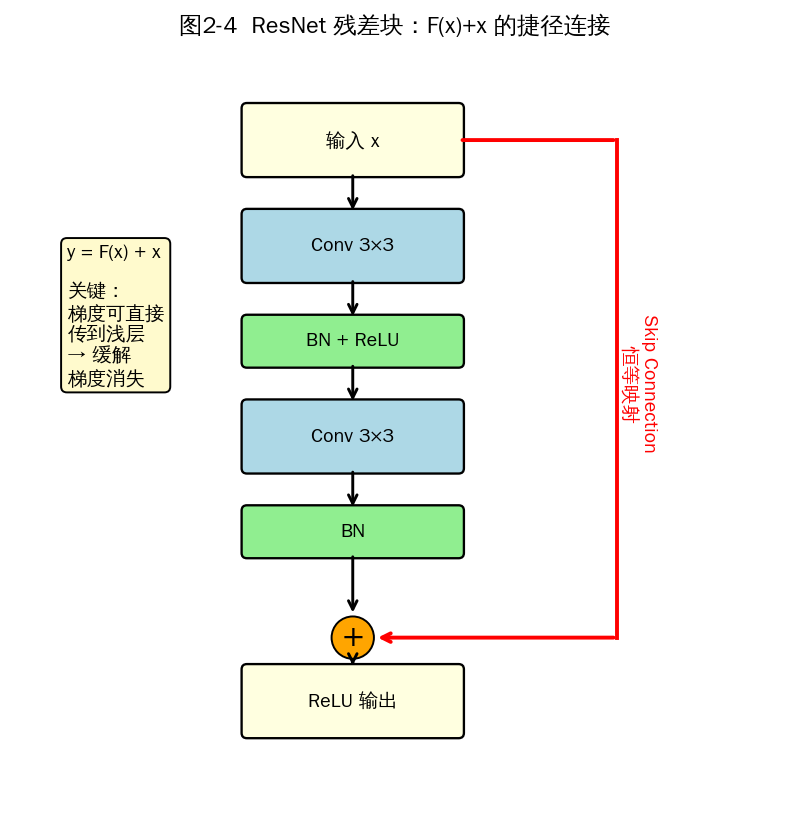
图2-4 ResNet 残差块:通过 skip connection 让梯度直通浅层
2.2.6 DenseNet (2017, Huang et al.)
- 在 ResNet"相加"基础上更进一步:每层与前面所有层在通道维上拼接(concatenate)。
- 每一层都能直接访问前面所有层的特征 → 特征复用最大化。
- 参数效率高,相同精度下参数比 ResNet 少。
- 代价:显存开销大(需保留所有中间特征图用于拼接)。
- 引入 transition 层(Conv 1×1 + AvgPool)控制通道数膨胀。
2.3 卷积层有哪些基本参数
- kernel_size(卷积核大小):常见 1×1、3×3、5×5、7×7。
- in_channels / out_channels:输入/输出通道数。
- stride(步长):滑窗每次移动的像素数,常见 1 或 2。
- padding(填充):在输入边缘填零,控制输出尺寸。"same"=输出尺寸等于输入;"valid"=不填零。
- dilation(膨胀率/空洞率):卷积核中元素之间的间距,用于空洞卷积。
- groups(分组数):将输入通道分组分别卷积,分组卷积 / depthwise 卷积的核心参数。
- bias:是否添加偏置项(接 BN 时通常设 False)。
2.4 如何计算卷积层的输出大小
对于二维卷积,输出特征图尺寸为:
H_out = ⌊ (H_in + 2·padding − dilation·(kernel − 1) − 1) / stride ⌋ + 1
W_out 同理
特殊情况(dilation=1 时):
H_out = ⌊ (H_in + 2P − K) / S ⌋ + 1
举例:输入 224×224,使用 kernel=7、stride=2、padding=3:
H_out = (224 + 6 - 7)/2 + 1 = 112
再经过 stride=2 的最大池化:112/2 = 56。继续 stride=2 卷积 → 28、14、7,最终经 GAP 输出特征向量。这就是 ResNet 中标准的特征图尺寸序列。
2.5 如何计算卷积层参数数量
参数量 = (kernel_h × kernel_w × in_channels) × out_channels + out_channels(偏置)
其中括号内是一个卷积核的参数量,乘以 out_channels 是因为有这么多个滤波器,最后 + out_channels 是偏置(若有)。
举例:3×3 卷积、in=64、out=128:
3 × 3 × 64 × 128 + 128 = 73,856
对比 FLOPs(每张输入的浮点运算次数):
FLOPs = H_out × W_out × kernel_h × kernel_w × in_channels × out_channels
2.6 有哪些池化方法
- 最大池化(Max Pooling):取窗口内最大值,保留最显著特征,是分类网络中最常用的。
- 平均池化(Average Pooling):取窗口内均值,更平滑,常用于早期网络。
- 全局平均池化(GAP):对每个通道整张图取平均,得到一个标量,常用于替代 FC(NIN、ResNet 后期)。
- 随机池化(Stochastic Pooling):按激活值概率随机采样。
- 混合池化(Mixed Pooling):max 和 average 加权组合。
- LP 池化(LP Pooling):广义 p 范数池化。
- ROI Pooling / ROI Align:目标检测中将不同大小的候选框对齐到固定尺寸。
- Spatial Pyramid Pooling(SPP):多尺度池化拼接,使网络可以处理任意大小输入。
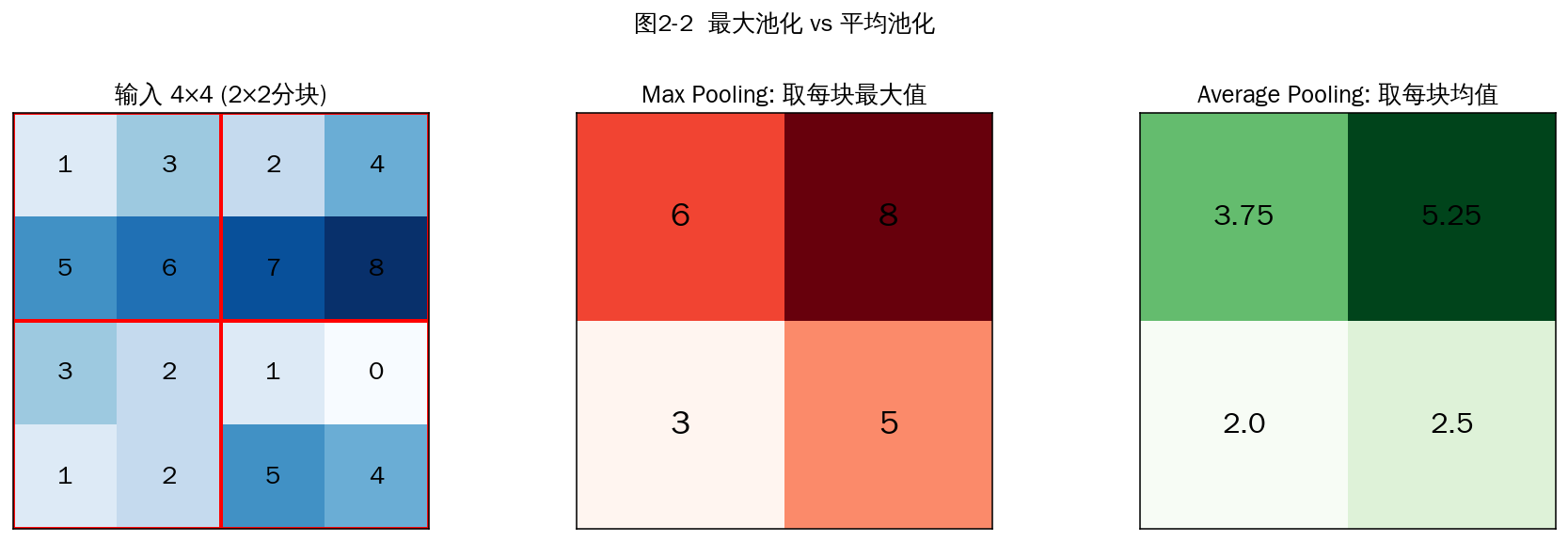
图2-2 最大池化(保留极值)vs 平均池化(保留整体趋势)
2.7 1×1 卷积的作用
- 通道维度变换(升维或降维):例如 256 通道 → 64 通道,参数量极小(256·64=16K)。
- 跨通道信息整合:在不改变空间尺寸的前提下,让不同通道间做线性组合。
- 引入非线性:1×1 卷积后接 ReLU,相当于增加一次非线性变换。
- 计算瓶颈结构(bottleneck):ResNet 的 1×1→3×3→1×1 结构,先降维再升维,大幅减少 3×3 卷积的计算量。
- Inception 的核心:用 1×1 卷积在多分支前做降维,使 Inception 模块计算可控。
2.8 卷积层和池化层有什么区别
卷积层 | 池化层 | |
是否有参数 | 有可学习参数(权重 + 偏置) | 无可学习参数 |
作用 | 提取特征 | 下采样、降维、提供平移不变性 |
是否改变通道数 | 可以改变 | 保持通道数不变 |
是否引入非线性 | 本身是线性运算 | Max Pooling 是非线性的 |
反向传播 | 梯度按权重传递 | Max 仅传给最大值位置;Avg 均分给每个位置 |
2.9 卷积核是否一定越大越好
不是。早期 CNN 用 11×11、7×7 等大卷积核,现代网络更倾向于"小卷积核+深层堆叠"。
大卷积核的问题:
- 参数量大:7×7 卷积参数是 3×3 的 5.4 倍。
- 计算量大:FLOPs 也按平方增长。
- 感受野虽大,但缺少层间的多次非线性变换。
小卷积核 + 深层堆叠的优势:
- 两个 3×3 等效于 5×5 感受野,参数少 28%。
- 三个 3×3 等效于 7×7 感受野,参数少 45%。
- 引入更多 ReLU,非线性表达能力更强。
例外:最初的输入处理层有时仍用 7×7(如 ResNet 的 stem),快速扩大感受野并降低分辨率。
2.10 卷积在图像中有什么直观作用
卷积本质上是用模板(卷积核)在图像上扫描并做加权求和。不同卷积核执行不同特征提取:
- 平滑/模糊:均值核、高斯核。
- 边缘检测:Sobel、Prewitt、Laplacian 核可检测水平/垂直/斜向边缘。
- 锐化:Laplacian 锐化核增强边缘。
- 浮雕、纹理提取等。
深度网络中,浅层卷积核学到的就是类似 Sobel/Gabor 的边缘和纹理检测器,中层学到部件,高层学到物体级语义。
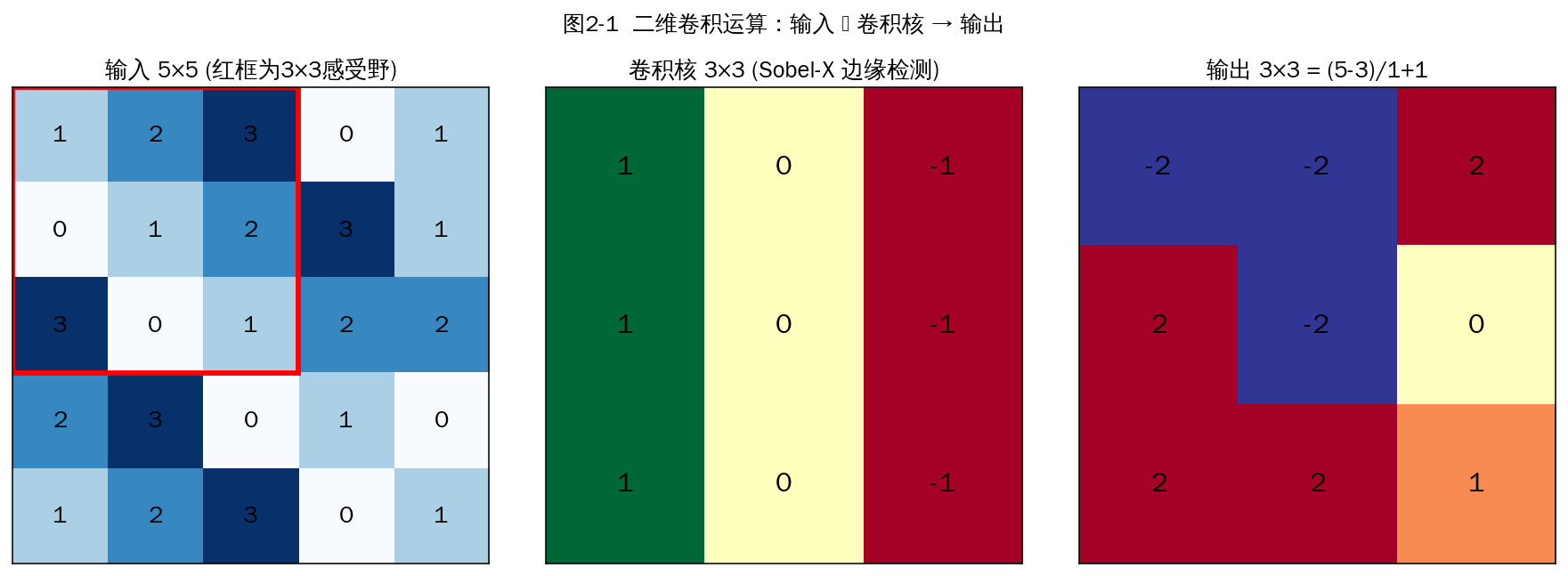
图2-1 二维卷积运算(左:输入;中:Sobel-X 边缘检测核;右:输出特征图)
2.11 CNN 中空洞卷积(Dilated/Atrous Convolution)的作用是什么
空洞卷积在标准卷积核元素之间插入 (dilation-1) 个零,相当于卷积核被"撑大",但参数量不变。
感受野 = (kernel - 1) × dilation + 1
例如 3×3 卷积、dilation=2 时,感受野等同于 5×5;dilation=4 时等同于 9×9。
作用:
- 不增加参数和计算量的前提下,指数级扩大感受野。
- 保持特征图分辨率:传统下采样(池化、stride)会丢失空间信息,空洞卷积可避免。
- 在语义分割(DeepLab)、目标检测、语音建模(WaveNet)中广泛使用。
注意:要避免"网格效应"(连续多次相同 dilation 会让某些像素无法被感知),常用 HDC(Hybrid Dilated Convolution,dilation 错开取值)解决。
2.12 怎样才能减少卷积层参数量
- 使用更小的卷积核(3×3 替代 5×5/7×7)。
- Bottleneck 结构:1×1 降维 → 3×3 → 1×1 升维(ResNet/Inception)。
- 深度可分离卷积(Depthwise Separable Conv):将标准卷积分解为 depthwise(每通道独立)+ pointwise(1×1 跨通道),参数减少约 8~9 倍,MobileNet 核心。
- 分组卷积(Group Convolution):将通道分成 G 组分别卷积,参数减为 1/G,ResNeXt 用 32 组。
- 1×1 卷积做通道压缩。
- 全局平均池化(GAP)替代 FC:VGG 的 FC 层有 1.2 亿参数,换成 GAP 后参数大幅减少。
- 知识蒸馏 + 量化 + 剪枝(部署阶段)。
深度可分离卷积参数对比:
标准 3×3 卷积: 3×3×C_in×C_out
Depthwise + Pointwise: 3×3×C_in + C_in×C_out ≈ 减少 (1/C_out + 1/9) 倍
2.13 在进行卷积操作时,必须同时考虑通道和区域吗
标准卷积同时处理空间(H×W)和通道(C)信息,参数 = K×K×C_in×C_out。但这两类信息可以解耦:
- Depthwise 卷积:每个通道独立做空间卷积(不跨通道)。
- Pointwise 卷积(1×1):只做跨通道线性组合(不做空间聚合)。
- 两者结合 = Depthwise Separable Conv,分别建模空间和通道相关性。
结论:不必同时考虑。空间相关性与通道相关性可以解耦建模,是轻量级网络(MobileNet、Xception)的核心思想。
2.14 采用宽卷积、窄卷积的好处有什么
- 窄卷积(Narrow/Valid):不做 padding,输出尺寸小于输入。优点:无边界假数据;缺点:多层后特征图迅速缩小,深层网络不友好。
- 宽卷积(Wide/Full):padding=K-1,输出尺寸大于输入。可保留更多边界信息,NLP 中文本卷积常用。
- Same Padding(最常用):padding=(K-1)/2,输入输出尺寸相等,便于堆叠和残差连接。
2.15 介绍反卷积(转置卷积)
反卷积(Transposed Convolution / Deconvolution,更准确的名称是"转置卷积")用于上采样:将小特征图"放大"成大特征图,是分割(U-Net)、生成(DCGAN、Pix2Pix)的关键操作。
原理:
普通卷积可表示为矩阵乘法 y = C·x,其中 C 是稀疏的卷积矩阵;转置卷积就是 x = Cᵀ·y,即用 C 的转置完成"由输出反推输入"的形状变换(但不是真正的逆运算)。
实现:
- 先在输入特征图的元素之间插零(stride 决定插零数)。
- 再做普通卷积。
- PyTorch 中:nn.ConvTranspose2d(in, out, K, stride, padding)。
棋盘效应(Checkerboard Artifact):
当 stride 不能被 kernel 整除时,输出会出现规则的明暗格子。解决方法:用"双线性插值上采样 + 普通卷积"代替转置卷积(如 PixelShuffle、UpSample+Conv)。
2.16 如何提高卷积神经网络的泛化能力
- 数据层面:扩充数据集、强数据增强(RandAugment、MixUp、CutMix、Mosaic)。
- 正则化:Weight Decay、Dropout、Stochastic Depth、DropBlock、Label Smoothing。
- 架构选择:合适深度和宽度、残差连接、归一化层。
- 训练技巧:合理学习率调度(Cosine、Warmup)、EMA 权重平均、SWA(Stochastic Weight Averaging)。
- 迁移学习:用大数据集(ImageNet/JFT)预训练,再在目标任务微调。
- 集成方法:训练多个模型投票、Snapshot Ensemble。
- 知识蒸馏:用大模型指导小模型。
- 自监督预训练:MoCo、SimCLR、MAE、DINO 等,先在无标注数据上预训练。
2.17 卷积神经网络在 NLP 与 CV 领域应用的区别
CV (图像) | NLP (文本) | |
输入形状 | 2D/3D 张量 (H,W,C) | 1D 序列 (Token, Embedding_dim) |
卷积维度 | 2D 卷积 | 1D 卷积(沿时间/序列轴) |
卷积核形状 | k×k | k×embedding_dim(覆盖整个词向量维度) |
平移不变性 | 强(物体可出现在任何位置) | 弱(词序有意义) |
典型用法 | 特征提取、分类、检测 | TextCNN 分类、字符级语言模型 |
现状 | 仍是 CV 主流 | 主流已转向 Transformer |
2.18 全连接、局部连接、全卷积与局部卷积的区别
- 全连接(Fully Connected):每个输出与每个输入都有独立权重,参数量 = N_in × N_out。
- 局部连接(Locally Connected):仅与输入的局部窗口相连,但不同位置使用不同权重(不共享)。参数量介于卷积和 FC 之间。
- 全卷积(Fully Convolutional, FCN):网络中没有任何全连接层,全部由卷积组成,可处理任意尺寸输入。语义分割(FCN、U-Net、DeepLab)的核心。
- 局部卷积(Locally Connected)= 不权值共享的卷积,适合人脸识别(不同区域学不同特征)。
2.19 卷积层和全连接层的区别
卷积层 | 全连接层 | |
连接方式 | 局部连接 + 权值共享 | 全连接,无权值共享 |
参数量 | 小 | 巨大(参数瓶颈) |
空间结构 | 保留空间结构(输出仍是特征图) | 破坏空间结构(输入需要 Flatten) |
输入尺寸 | 可变(任意 H×W) | 固定(必须为预设维度) |
典型用途 | 特征提取 | 最后分类决策(或被 GAP 替代) |
💡 提示: 一个全连接层可以等价于 1×1 卷积(输入空间大小为 1×1 时)。这一观察催生了全卷积网络(FCN),让网络可以接受任意尺寸输入。
2.20 Max pooling 如何工作?还有其他池化技术吗
Max Pooling 的工作流程:
- 定义窗口大小(通常 2×2)和步长(通常等于窗口大小,无重叠)。
- 滑动窗口,每个位置取窗口内最大值。
- 输出特征图尺寸缩小(如 28×28 → 14×14)。
反向传播:梯度只回传给窗口内最大值的位置,其他位置梯度为 0。
其他池化技术(详见 2.6):Average Pooling、Global Average Pooling、Stochastic Pooling、ROI Pooling、ROI Align、SPP(空间金字塔池化)。
2.21 卷积神经网络的优点?为什么用小卷积核
CNN 优点:
- 参数共享:同一卷积核扫过整张图,大幅减少参数。
- 局部连接:契合图像的局部相关性,提供归纳偏置。
- 平移不变性:池化和共享带来一定平移鲁棒。
- 层次化特征:浅层学边缘,中层学部件,深层学语义。
- 对大数据可扩展,硬件友好。
小卷积核的优势:
- 参数和计算量少:3×3 比 5×5 减少 28%,比 7×7 减少 81%。
- 堆叠多个 3×3 可达到相同感受野,但引入更多非线性。
- GPU 对 3×3 卷积有专门优化(如 Winograd 算法),实测速度更快。
2.22 CNN 拆成 3×1 1×3 的优点
Inception-V3 中提出的"卷积核分解"技巧:将 3×3 卷积拆成 3×1 + 1×3 两个非对称卷积。
优点:
- 参数减少:3×3=9 个参数 vs 3+3=6 个参数,节省 33%。
- 计算量减少同比例。
- 引入一次额外的非线性激活,理论表达能力更强。
- 对大卷积核(5×5、7×7)拆解收益更大。
限制:对小卷积核(3×3)增益有限;对感受野要求高的浅层不宜过早使用。
2.23 BN、LN、IN、GN 和 SN 的区别
五种归一化方法的本质区别在于"对哪些维度统计均值方差"。设输入张量形状为 (N, C, H, W):
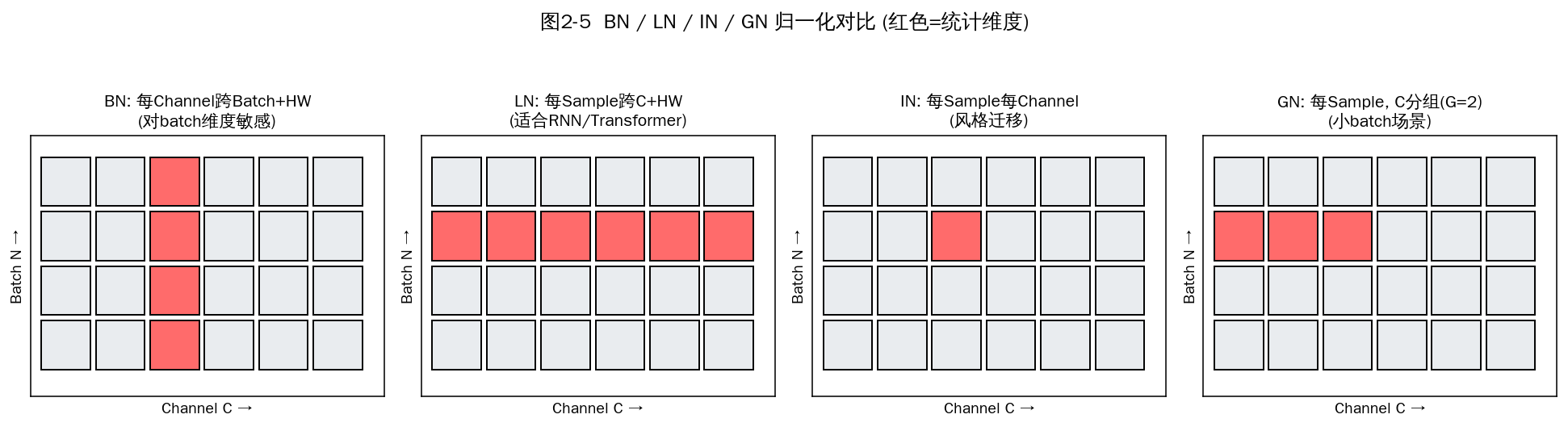
图2-5 BN / LN / IN / GN 归一化对比(红色为统计维度,每格代表一个 H×W 平面)
方法 | 统计维度 | 适用场景 | 对 batch 是否敏感 |
BN | 对每个 C,跨 (N, H, W) 求均值方差 | CV 大 batch 训练 | 敏感(batch<8 性能下降) |
LN(Layer Norm) | 对每个 N,跨 (C, H, W) | RNN、Transformer | 不敏感 |
IN(Instance Norm) | 对每个 (N, C),跨 (H, W) | 风格迁移、GAN | 不敏感 |
GN(Group Norm) | 对每个 N,C 分 G 组,每组跨 (H, W) | 检测/分割(小 batch) | 不敏感 |
SN(Switchable Norm) | 自适应学习 BN/LN/IN 三者权重 | 通用 | 部分敏感 |
🔑 要点: 实践要点:CV 默认 BN;RNN/Transformer 默认 LN;目标检测、分割等 batch 很小时改 GN;GAN/风格迁移用 IN。
三、循环神经网络(RNN)
循环神经网络专为序列数据设计,通过隐状态在时间维度上的循环传递实现"记忆"。RNN 是 NLP、语音、时间序列建模的传统主力,虽然 Transformer 已在多数任务上取代它,但 RNN 的核心思想(隐状态、序列依赖)仍是深度学习的基础概念。
3.1 RNNs 训练和传统 ANN 训练异同点
相同点:
- 都使用反向传播 + 梯度下降优化。
- 都通过链式法则计算梯度。
- 都需要正则化、归一化、初始化等通用技巧。
不同点:
- RNN 使用 BPTT(Backpropagation Through Time,时间反向传播):将循环网络按时间展开成深度网络,再做标准反向传播。
- 参数共享:所有时间步共用同一组权重 W_xh、W_hh、W_hy。梯度需要在所有时间步上累加。
- 梯度消失/爆炸更严重:因为时间步可能很长(几十到几百),梯度连乘次数远多于普通深度网络。
- Truncated BPTT:实际训练中通常只反向传播 K 个时间步(K 远小于序列长度),平衡效率与依赖范围。
- 输入是变长序列,需要 padding + mask 或 packed sequence 处理。
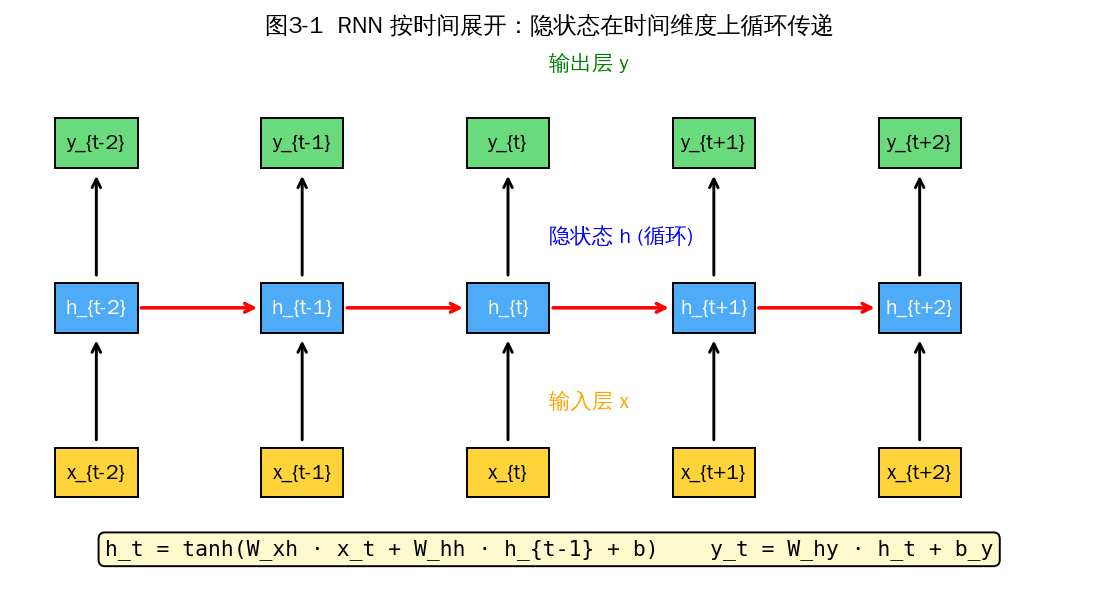
图3-1 RNN 按时间展开:隐状态 h_t 接收当前输入 x_t 与上一时刻 h_{t-1}
3.2 为什么 RNN 训练的时候 Loss 波动很大
- 梯度爆炸/消失:长序列 BPTT 导致梯度量级在时间维度上剧烈变化,参数更新不稳定。
- 序列长度不同:每个 batch 内序列长度差异大,loss 量级不同。
- 参数共享放大噪声:同一参数在所有时间步上累加梯度,单步噪声被放大。
- 损失曲面陡峭:RNN 的损失曲面充满悬崖(cliff),梯度突然变大导致大步跳跃。
缓解方法:
- 梯度裁剪:clip_grad_norm 到 1.0~5.0。
- 使用 LSTM/GRU 替代标准 RNN。
- 降低学习率(RNN 常用 1e-3 ~ 1e-4)。
- Layer Normalization 替代 Batch Normalization。
3.3 RNN 中为什么会出现梯度消失
考虑标准 RNN 的隐状态更新:
h_t = tanh(W_hh · h_{t-1} + W_xh · x_t + b)
计算 ∂L/∂h_0 时,需要经过 T 次链式法则:
∂h_t / ∂h_{t-1} = diag(1 - h_t²) · W_hh
∂L / ∂h_0 = Π_{t=1..T} (∂h_t / ∂h_{t-1}) ≈ (W_hh)^T · tanh'(·)^T
如果 W_hh 的最大特征值 < 1,梯度在时间维呈指数衰减(消失);> 1 则指数增长(爆炸)。
而 tanh'(·) 最大为 1(在 0 处),饱和区接近 0,进一步加剧梯度消失。
3.4 如何解决 RNN 中的梯度消失问题
- 使用 LSTM / GRU:门控机制为梯度提供"高速通道"(cell state),不经过反复的 tanh 衰减。
- 合理初始化:使用单位矩阵初始化 W_hh(IRNN)或正交初始化(让 ‖W_hh‖₂ ≈ 1)。
- 梯度裁剪:主要解决爆炸;消失需要架构改进。
- 使用 ReLU 替代 tanh(但需配合正交初始化或单位矩阵初始化,否则容易爆炸)。
- Layer Normalization:让每个时间步的激活分布稳定。
- 残差连接:跨时间步的 skip connection。
- 从根本上:用 Transformer / Self-Attention 替代 RNN,路径长度从 O(T) 降到 O(1)。
3.5 CNN VS RNN
CNN | RNN | |
处理数据 | 图像、空间网格 | 序列、时间数据 |
连接方式 | 局部连接 + 权值共享 | 时间循环 + 权值共享 |
关键归纳偏置 | 平移不变性 | 时间不变性 |
并行性 | 高(每层可并行) | 低(必须按时间顺序) |
长程依赖 | 需深层堆叠或空洞卷积 | LSTM/GRU 支持,但 >100 步仍困难 |
训练稳定性 | 高 | 较低(梯度消失/爆炸) |
现状 | CV 主力,部分被 ViT 替代 | 基本被 Transformer 替代 |
3.6 Keras 搭建 RNN
文本分类的 RNN 示例:
import tensorflow as tf
from tensorflow.keras import layers, models
vocab_size = 10000
embed_dim = 128
max_len = 100
model = models.Sequential([
layers.Embedding(vocab_size, embed_dim, input_length=max_len),
layers.Bidirectional(layers.LSTM(64, return_sequences=True)),
layers.Bidirectional(layers.LSTM(32)),
layers.Dense(64, activation='relu'),
layers.Dropout(0.3),
layers.Dense(1, activation='sigmoid') # 二分类
])
model.compile(optimizer=tf.keras.optimizers.Adam(1e-3),
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=64,
validation_data=(x_val, y_val))
四、长短期记忆网络(LSTM)
LSTM 由 Hochreiter & Schmidhuber 于 1997 年提出,通过精心设计的"门控机制"解决了标准 RNN 的梯度消失问题,成为 2014~2018 年间 NLP/语音领域的主力架构。
4.1 LSTM 结构推导,为什么比 RNN 好
LSTM 引入两条信息流:cell state C(长期记忆)和 hidden state h(短期记忆),通过三个门控制信息的读写擦除。
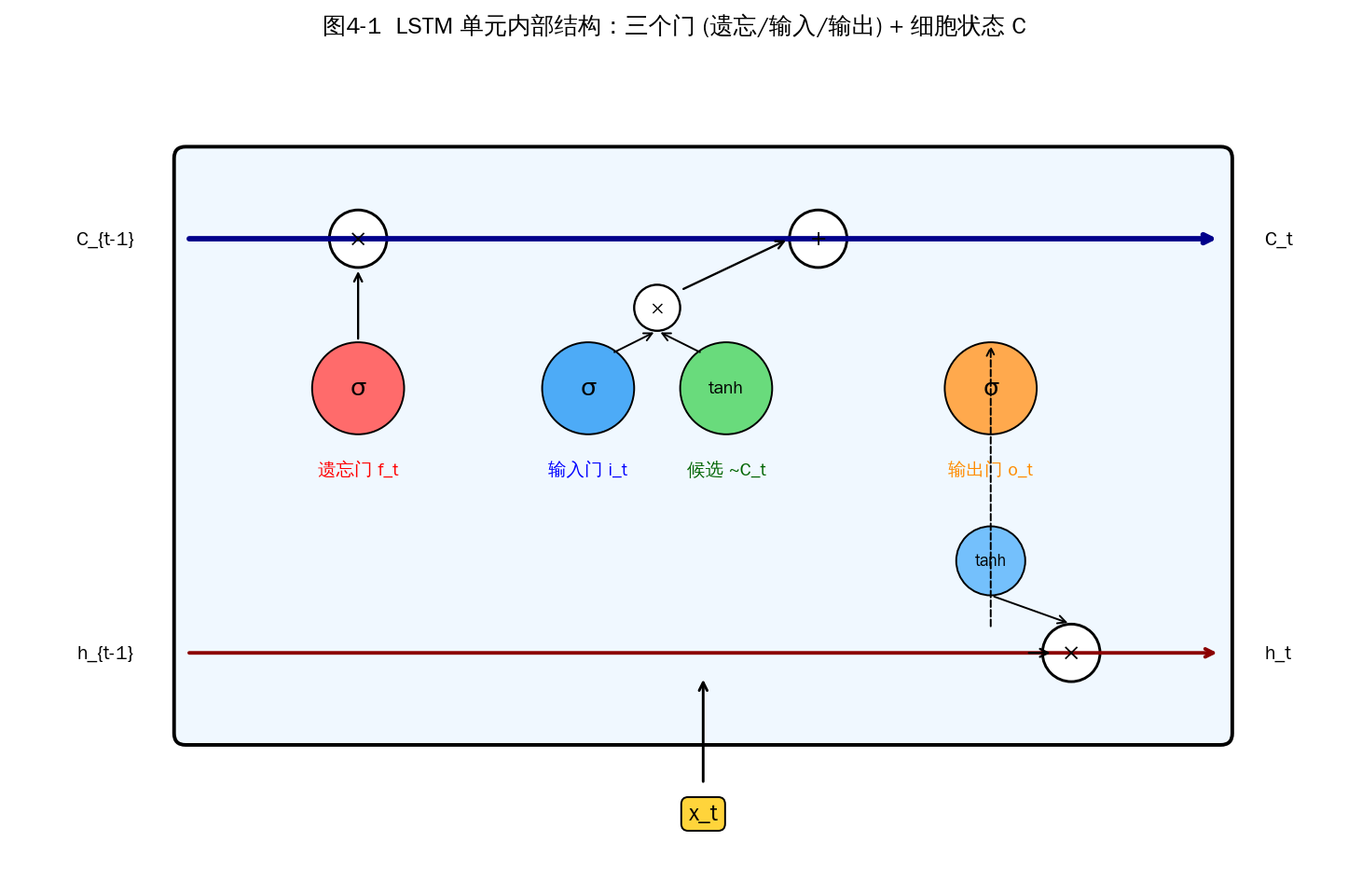
图4-1 LSTM 单元内部结构:遗忘门、输入门、输出门 + 细胞状态 C
完整公式(输入 x_t,前一状态 h_{t-1}, C_{t-1}):
f_t = σ(W_f · [h_{t-1}, x_t] + b_f) 遗忘门
i_t = σ(W_i · [h_{t-1}, x_t] + b_i) 输入门
~C_t = tanh(W_C · [h_{t-1}, x_t] + b_C) 候选细胞状态
C_t = f_t ⊙ C_{t-1} + i_t ⊙ ~C_t 更新细胞状态
o_t = σ(W_o · [h_{t-1}, x_t] + b_o) 输出门
h_t = o_t ⊙ tanh(C_t) 隐状态输出
其中 σ 是 Sigmoid,输出 [0,1] 起"门"的作用;⊙ 是逐元素相乘。
为什么比 RNN 好:
- 梯度高速通道:cell state 的更新 C_t = f_t ⊙ C_{t-1} + i_t ⊙ ~C_t 是加法形式(而非 RNN 的 tanh(W·h)),梯度可直接沿 cell state 传递,不会指数衰减。
- 门控可选择性遗忘 / 记忆:模型自适应决定保留什么、忘掉什么。
- 对长程依赖更友好:理论上可处理 100+ 时间步的依赖。
- 训练更稳定:实践中 loss 曲线比 RNN 平滑得多。
4.2 为什么 LSTM 模型中既存在 sigmoid 又存在 tanh 两种激活函数,而不是选择统一一种 sigmoid 或者 tanh
两者在 LSTM 中扮演不同角色,不能互换:
Sigmoid 用于门(gate):
- 输出范围 [0, 1],恰好对应"完全保留(1) / 完全遗忘(0) / 部分通过(0.5)"的开关语义。
- 用于 f_t, i_t, o_t 三个门。
Tanh 用于状态值:
- 输出范围 [-1, 1],零均值,使 cell state 可以正向或负向编码信息,且数值范围有界(避免无限增长)。
- 用于候选 ~C_t 和 h_t 的输出激活。
如果都用 sigmoid,状态值无法为负,表达能力受限;如果都用 tanh,门无法表达"完全关闭"(tanh(0)=0 但 tanh 不能在饱和区给出 0~1 的概率语义)。
4.3 LSTM 中为什么经常是两层双向 LSTM
双向 LSTM(Bi-LSTM)同时使用前向和后向两个 LSTM,将两者的隐状态拼接:
h_t = [→h_t ; ←h_t]
优点:
- 上下文双向感知:当前 token 的表示同时融合了过去和未来信息(对句子级 NLU 至关重要)。
- 提升表达能力:单向只能从左到右建模,双向可捕捉双向语义依赖。
为什么用两层:
- 单层 Bi-LSTM 表达能力有限;两层能学到更高级的语义特征。
- 层数过多(3+)训练不稳定且收益递减。
- 两层是性能/效率/稳定性的常见折中。
⚠️ 注意: 注意:Bi-LSTM 不适用于"在线/流式"场景(如实时语音识别),因为需要看到完整序列。这种情况下只能用单向。
4.4 RNN 扩展改进
4.4.1 Bidirectional RNNs
如上文所述,由两个方向相反的 RNN 组成,输出拼接两者的隐状态。常见于命名实体识别、机器翻译编码器等。
4.4.2 CNN-LSTMs
先用 CNN 提取局部特征,再用 LSTM 建模时序。典型应用:
- 视频分类:CNN 抽取每帧特征,LSTM 建模帧间时序。
- OCR:CNN 提取图像特征,LSTM/CTC 解码为文字。
- 语音识别:CNN 提取声学特征,LSTM 建模发音序列。
4.4.3 Bidirectional LSTMs
Bi-LSTM 是 Bi-RNN 用 LSTM 替换标准 RNN 的版本,是 NLP 中长期的事实标准(被 BERT/Transformer 替代之前)。
4.4.4 GRU(Gated Recurrent Unit)
Cho 等人于 2014 年提出,是 LSTM 的简化版:将 LSTM 的"输入门 + 遗忘门"合并为"更新门",去掉单独的 cell state。
z_t = σ(W_z · [h_{t-1}, x_t]) 更新门
r_t = σ(W_r · [h_{t-1}, x_t]) 重置门
~h_t = tanh(W · [r_t ⊙ h_{t-1}, x_t]) 候选状态
h_t = (1 - z_t) ⊙ h_{t-1} + z_t ⊙ ~h_t 最终输出
优点:参数比 LSTM 少 ~25%,训练快;缺点:表达能力略弱,但在大多数任务上与 LSTM 性能相当。
4.5 LSTM、RNN、GRU 区别
RNN | LSTM | GRU | |
门数量 | 0 | 3(输入/遗忘/输出) | 2(更新/重置) |
状态 | 隐状态 h | 隐状态 h + 细胞状态 C | 隐状态 h |
参数量 | 最少 | 最多(约 4 倍 RNN) | 中等(约 3 倍 RNN) |
长程依赖 | 差(梯度消失) | 强 | 强(与 LSTM 接近) |
训练稳定性 | 低 | 高 | 高 |
训练速度 | 快 | 慢 | 中等 |
典型场景 | 短序列、教学 | 长序列、NLP/语音 | NLP、轻量场景 |
4.6 LSTM 是如何实现长短期记忆功能的
- 细胞状态 C 作为长期记忆载体:以加法方式更新,梯度沿 C 直接传递,不会消失。
- 遗忘门 f_t:决定保留多少旧记忆(C_{t-1})。当 f_t≈1 时,长期记忆可以传播极远;当 f_t≈0 时,主动遗忘。
- 输入门 i_t:决定将多少新信息写入 C。
- 输出门 o_t:决定将 C 中多少信息作为短期输出 h_t 暴露给下游层。
因此,"长期"由 cell state 承担(缓慢更新,可保存上百时间步前的信息);"短期"由 hidden state 承担(每步都重新计算)。
4.7 LSTM 的原理、写 LSTM 的公式、手推 LSTM 的梯度反向传播
原理与公式见 4.1。下面手推关键梯度:
设损失函数为 L,已知 ∂L/∂h_t 和 ∂L/∂C_t。
Step 1:计算对各门的梯度
∂L/∂o_t = (∂L/∂h_t) ⊙ tanh(C_t)
∂L/∂C_t += (∂L/∂h_t) ⊙ o_t ⊙ (1 - tanh²(C_t))
∂L/∂f_t = (∂L/∂C_t) ⊙ C_{t-1}
∂L/∂i_t = (∂L/∂C_t) ⊙ ~C_t
∂L/∂~C_t = (∂L/∂C_t) ⊙ i_t
Step 2:通过激活函数
∂L/∂a_o = ∂L/∂o_t ⊙ o_t ⊙ (1 - o_t) (σ'(x) = σ(x)(1-σ(x)))
∂L/∂a_f = ∂L/∂f_t ⊙ f_t ⊙ (1 - f_t)
∂L/∂a_i = ∂L/∂i_t ⊙ i_t ⊙ (1 - i_t)
∂L/∂a_C = ∂L/∂~C_t ⊙ (1 - ~C_t²) (tanh'(x) = 1-tanh²)
Step 3:累积权重梯度(4 个矩阵均按时间累加)
∂L/∂W_f += ∂L/∂a_f · [h_{t-1}, x_t]ᵀ
其他 W_i、W_C、W_o 类似。
Step 4:向前一时间步传递
∂L/∂C_{t-1} = (∂L/∂C_t) ⊙ f_t 关键:梯度乘以 f_t 而不是 tanh 导数
∂L/∂h_{t-1} = (Σ_gate ∂L/∂a_gate · W_gate)[h 部分]
🔑 要点: 关键观察:cell state 的梯度只乘以 f_t(一个 sigmoid 输出,可控),不像普通 RNN 要乘 tanh 导数 + W_hh 的特征值。这就是 LSTM 缓解梯度消失的本质原因。
五、反向传播(Backpropagation)
反向传播是神经网络训练的核心算法,由 Rumelhart、Hinton 和 Williams 于 1986 年系统化提出。其本质是利用链式法则,将损失函数对参数的梯度从输出层逐层回传到每个参数,从而支持梯度下降优化。
5.1 什么是反向传播
反向传播(Backpropagation, BP)是一种高效计算神经网络中所有参数对损失函数梯度的算法。它基于微积分中的链式法则,从输出层开始,按计算图逆向逐层计算梯度,时间复杂度与前向传播相当(O(参数量))。
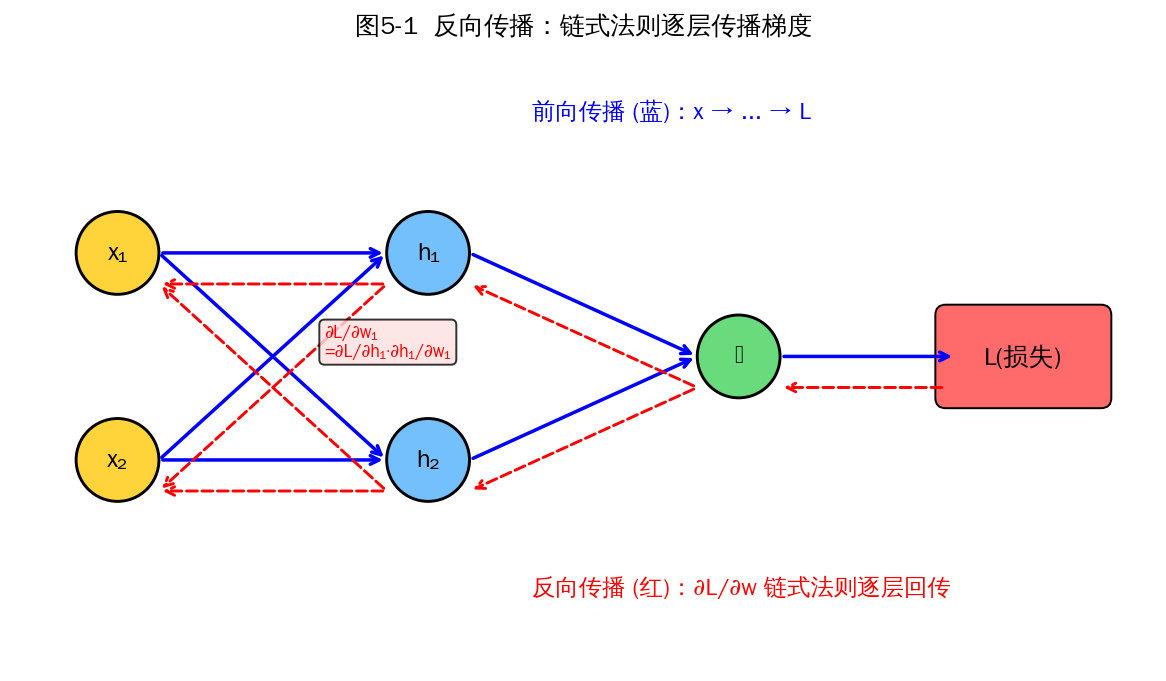
图5-1 反向传播示意:蓝色为前向计算,红色虚线为梯度逆向传播
关键概念:
- 计算图(Computational Graph):将复合函数表示为节点和边,每个节点是一个原子运算。
- 链式法则:∂L/∂x = (∂L/∂y) · (∂y/∂x),把整体梯度分解为局部梯度的乘积。
- 自动微分(Autograd):PyTorch、TensorFlow 通过记录计算图自动实现反向传播,无需手写。
5.2 反向传播是如何工作的
以三层 MLP 为例,演示完整流程:
网络:x → [W₁, b₁] → a₁=σ(z₁) → [W₂, b₂] → a₂=σ(z₂) → [W₃, b₃] → ŷ → L(ŷ, y)
前向传播:
z₁ = W₁·x + b₁, a₁ = σ(z₁)
z₂ = W₂·a₁ + b₂, a₂ = σ(z₂)
ŷ = W₃·a₂ + b₃, L = (1/2)(ŷ - y)²
反向传播(从右往左,逐层应用链式法则):
δ₃ = ∂L/∂ŷ = ŷ - y
∂L/∂W₃ = δ₃ · a₂ᵀ ∂L/∂b₃ = δ₃
δ₂ = (W₃ᵀ · δ₃) ⊙ σ'(z₂)
∂L/∂W₂ = δ₂ · a₁ᵀ ∂L/∂b₂ = δ₂
δ₁ = (W₂ᵀ · δ₂) ⊙ σ'(z₁)
∂L/∂W₁ = δ₁ · xᵀ ∂L/∂b₁ = δ₁
一般规律:每层的局部梯度 δ_l = (上一层 δ_{l+1} 通过权重 W_{l+1}ᵀ 反传) ⊙ 本层激活的导数。该层权重梯度 = δ_l 与输入的外积。
5.3 为什么需要反向传播
- 计算效率:要训练神经网络就要计算损失对所有参数的梯度。若用数值微分(有限差分),每个参数都需要一次完整前向计算,复杂度 O(参数量²)。反向传播仅需一次反向计算(与前向相当),复杂度 O(参数量),是唯一可行的算法。
- 精确性:数值微分有舍入误差和步长选择问题;反向传播(解析微分)给出精确梯度(除浮点误差外)。
- 通用性:任何由可微原子运算构成的计算图都能自动微分,无需对每个网络重新推导。
- 支持深度学习:没有 BP,训练 10 层以上的网络就不可行。
5.4 手推 BP
考虑最简单的二层网络做二分类,含一个隐层(ReLU)和 sigmoid 输出。批量大小 = 1,输入 x ∈ R^d,标签 y ∈ {0,1}。
前向传播:
z₁ = W₁·x + b₁ (W₁ ∈ R^{h×d}, b₁ ∈ R^h)
a₁ = ReLU(z₁) (∈ R^h)
z₂ = w₂·a₁ + b₂ (w₂ ∈ R^h, b₂ ∈ R)
ŷ = σ(z₂) = 1/(1+e^{-z₂}) (∈ (0,1))
L = -[y·log(ŷ) + (1-y)·log(1-ŷ)] (BCE 损失)
反向传播:
① 输出层梯度(Sigmoid + BCE 的优雅性质):
∂L/∂z₂ = ŷ - y (BCE+Sigmoid 抵消,得到非常简洁的表达)
② 输出层参数梯度:
∂L/∂w₂ = (ŷ - y) · a₁ᵀ
∂L/∂b₂ = ŷ - y
③ 传到隐层:
∂L/∂a₁ = (ŷ - y) · w₂
∂L/∂z₁ = ∂L/∂a₁ ⊙ ReLU'(z₁) = ∂L/∂a₁ ⊙ 𝟙(z₁ > 0)
④ 隐层参数梯度:
∂L/∂W₁ = ∂L/∂z₁ · xᵀ (外积,得到 h×d 矩阵)
∂L/∂b₁ = ∂L/∂z₁
参数更新:
W₁ ← W₁ - lr · ∂L/∂W₁, b₁ ← b₁ - lr · ∂L/∂b₁
w₂ ← w₂ - lr · ∂L/∂w₂, b₂ ← b₂ - lr · ∂L/∂b₂
🔑 要点: 面试常考:为什么交叉熵 + Sigmoid 比 MSE + Sigmoid 好?因为前者的 ∂L/∂z = ŷ-y 不含 σ'(z) 项,避免了饱和区梯度消失;后者的 ∂L/∂z = (ŷ-y)·ŷ·(1-ŷ) 在 ŷ 接近 0 或 1 时梯度极小。
第六章 生成对抗网络(GAN)
生成对抗网络(Generative Adversarial Network, GAN)由 Goodfellow 等人在 2014 年提出,是一类通过"对抗博弈"实现数据分布建模的生成模型。它包含两个相互对抗的网络:生成器(Generator, G)负责"造假",把随机噪声 z 映射为接近真实分布的样本 G(z);判别器(Discriminator, D)负责"辨真假",输出输入样本来自真实分布的概率 D(x)。两者通过 minimax 博弈共同优化:
min_G max_D V(D, G) = E_{x~p_data}[log D(x)] + E_{z~p_z}[log(1 - D(G(z)))]
理论上,当博弈达到全局最优时,G 学到了真实数据分布 p_data,D(x) 在任意点恒等于 1/2(无法区分真假)。但实际训练充满陷阱:模式崩溃、梯度消失、训练不稳定,由此衍生出 DCGAN、WGAN、StyleGAN 等一系列变体。
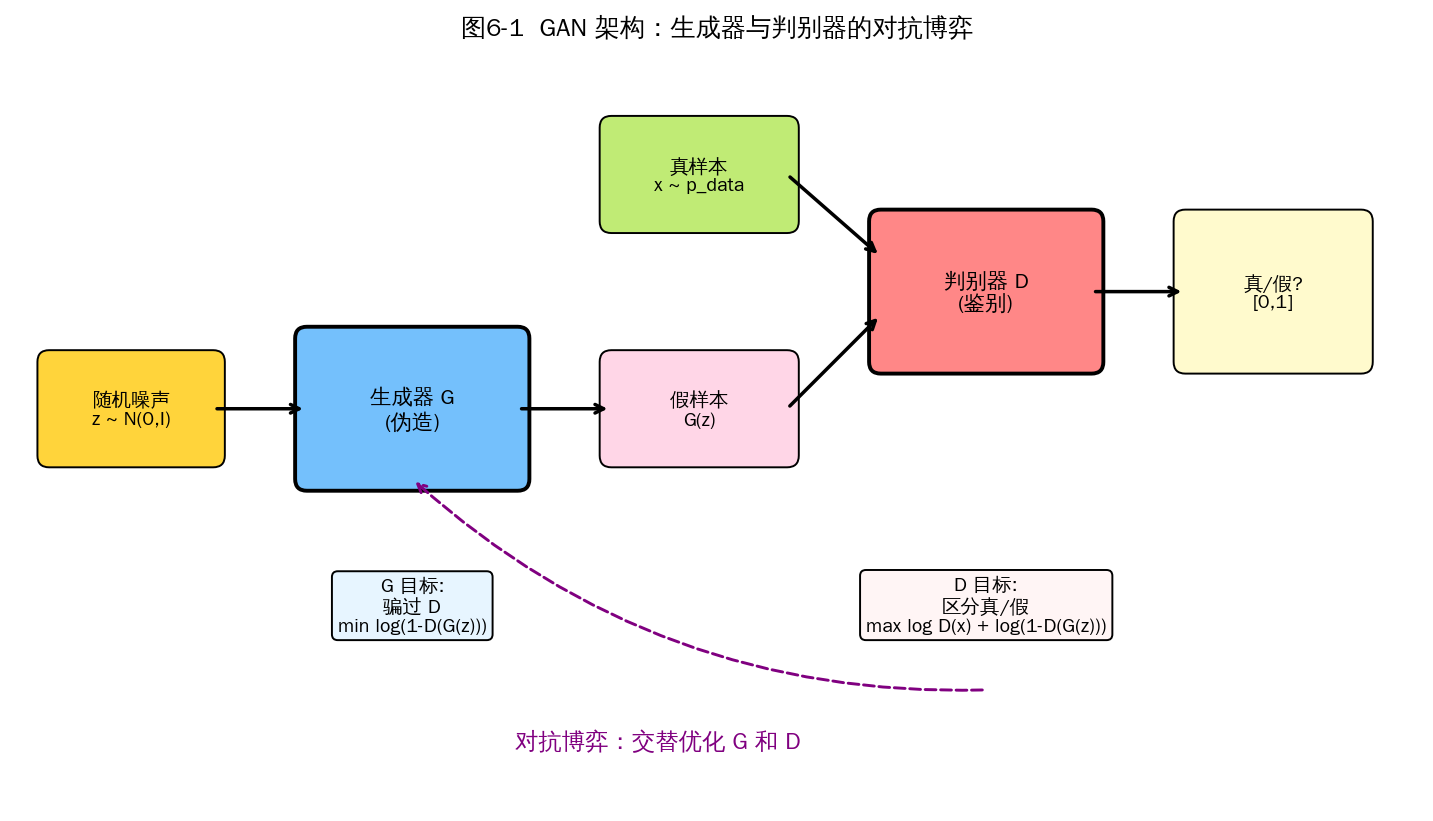
图6-1 GAN整体架构:G 和 D 的对抗博弈
6.1 生成器(Generator)
【作用】
生成器是一个可微分函数 G: Z → X,把低维的隐变量空间 Z(通常是各向同性高斯 N(0, I))映射到高维数据空间 X(图像 / 音频 / 文本等)。它的目标是让生成样本 G(z) 的分布 p_g 尽量逼近真实数据分布 p_data。
【典型结构(以 DCGAN 为例)】
DCGAN(Deep Convolutional GAN)确立了卷积生成器的事实标准:输入 100 维隐向量 z,通过一个全连接层 reshape 为 4×4×1024 的张量,然后通过若干层"转置卷积(Deconvolution / Transposed Convolution)"逐步上采样,最终输出 64×64×3 的彩色图像。
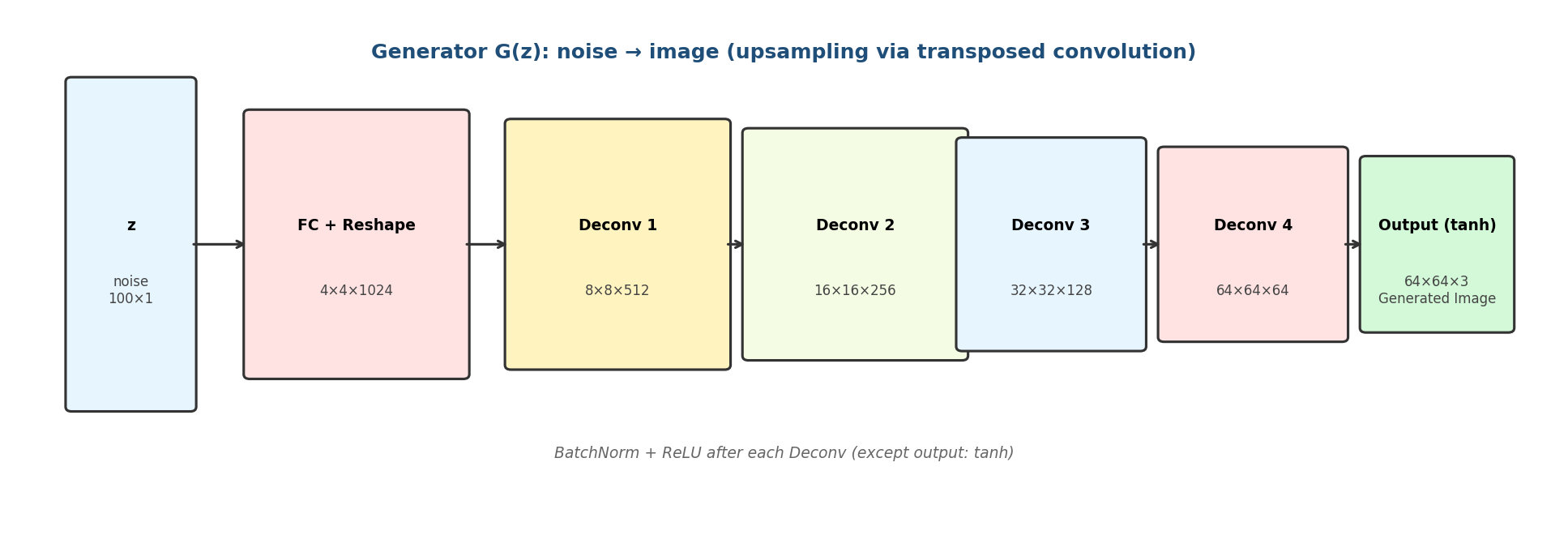
图6-2 DCGAN 生成器:噪声 → 图像的逐步上采样
【关键设计原则】
- 用转置卷积或 PixelShuffle 替代池化层,实现可学习的上采样。
- 每个隐藏层后接 BatchNorm + ReLU,加速收敛并稳定训练。
- 输出层使用 tanh 激活,把像素值映射到 [-1, 1](与真实图像预处理一致)。
- 避免在生成器中使用 dropout(会引入额外噪声,干扰生成质量)。
【上采样的三种主流方式】
方法 | 原理 | 优点 | 缺点 |
转置卷积 | 通过插零+卷积实现可学习上采样 | 端到端可训练;表达力强 | 容易产生"棋盘格伪影" |
Upsample+Conv | 先用 nearest/bilinear 上采样,再用普通卷积 | 伪影少;实现简单 | 可学习参数少 |
PixelShuffle | 把通道维 r²·C reshape 为空间维 (rH)×(rW) | 无伪影;ESRGAN 等超分常用 | 需配套设计输入通道数 |
📌 备注: "棋盘格伪影"产生的原因:当转置卷积的 kernel_size 不能被 stride 整除时,不同输出位置被卷积核覆盖的次数不均匀,造成周期性的亮度差。一个简单的修复:让 kernel_size 是 stride 的整数倍(如 4×4 stride 2),或者换用 Upsample+Conv。
【生成器的进阶变体】
- Progressive GAN(NVIDIA, 2017):从 4×4 分辨率开始,逐步加层升到 1024×1024,显著提升高分辨率生成质量。
- StyleGAN / StyleGAN2 / StyleGAN3:把隐向量 z 通过 mapping network 映射为 style 向量 w,通过 AdaIN(自适应实例归一化)在各分辨率层注入风格,实现属性解耦与精细控制。
- BigGAN(2018):超大 batch + 大模型 + 类别条件,在 ImageNet 上 256×256 生成达到 SOTA。
- 扩散模型(Diffusion,2020 起):用 U-Net 去噪迭代生成,已在很多场景超越 GAN(如 Stable Diffusion)。
6.2 判别器(Discriminator)
【作用】
判别器本质上是一个二分类器 D: X → [0, 1],输入一张图像,输出它来自真实数据集而非生成器的概率。它给 G 提供梯度信号:如果 D 能轻易区分真假,说明 G 还不够好;如果 D 也搞不清,说明 G 学得不错。
【典型结构(DCGAN 判别器)】
判别器结构基本是生成器的"镜像"——通过若干层 stride-2 卷积逐步下采样,最后 flatten 接全连接和 sigmoid。
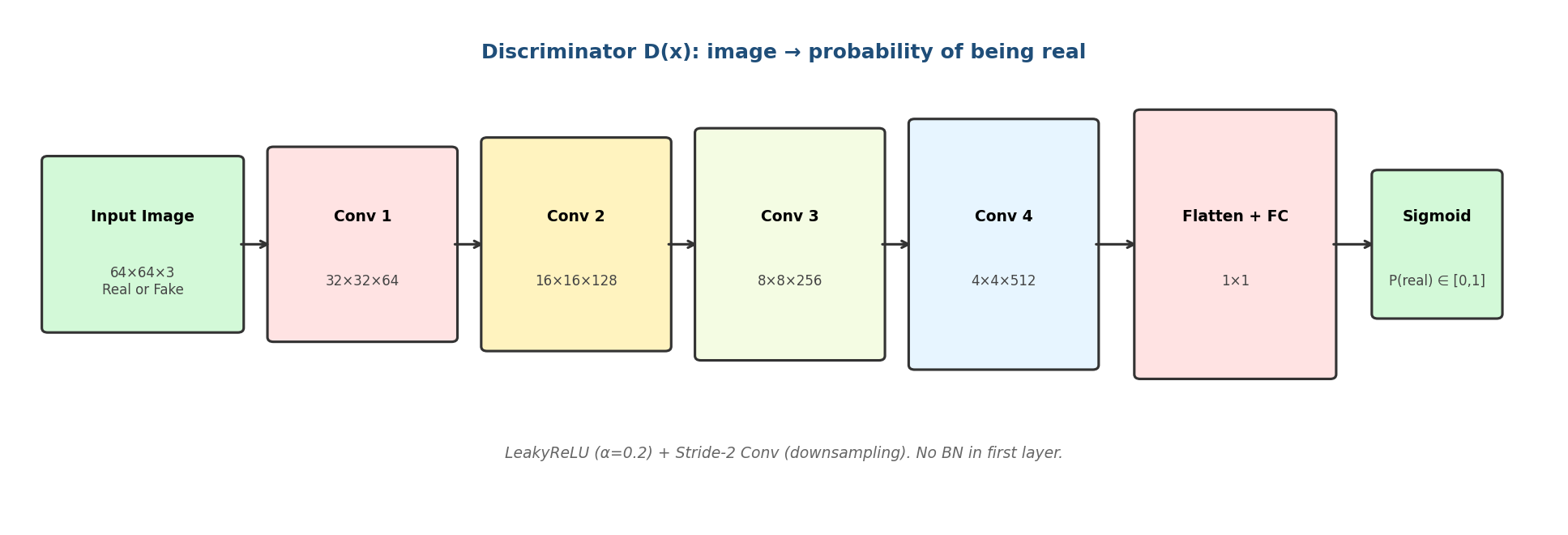
图6-3 DCGAN 判别器:图像 → 真假概率的逐步下采样
【关键设计原则】
- 用 stride-2 卷积替代池化,让下采样过程可学习。
- 使用 LeakyReLU(α=0.2)而不是 ReLU——LeakyReLU 在负区间有小斜率,能让 D 给 G 提供更稳定的梯度信号,避免 ReLU"死神经元"在对抗训练中放大问题。
- 第一层(输入层)一般不使用 BatchNorm,避免破坏输入分布;其余层均使用 BN(WGAN-GP 则用 LayerNorm)。
- 全卷积结构(无 padding 信息泄漏)有利于支持任意分辨率输入。
【判别器的进阶设计】
- PatchGAN(pix2pix):D 不输出全局的一个数,而是输出 N×N 的"patch 真假图",每个像素负责判断输入图中对应感受野(如 70×70)的局部 patch。这强迫 G 在细节纹理上更逼真,对图像翻译任务很有效。
- Spectral Normalization 谱归一化(SN-GAN, 2018):把 D 中每个卷积/全连接层的权重矩阵除以它的最大奇异值,保证 D 是 1-Lipschitz 函数。这是稳定 GAN 训练的"杀手锏",几乎成为标配。
- Self-Attention(SAGAN):在中间分辨率层引入自注意力,让 D 能捕获长程依赖(如物体的整体结构)。
- Projection Discriminator(cGAN-Projection):在条件 GAN 中,把类别 embedding 通过内积与中间特征相乘,比把 label concat 到 D 输入效果更好。
⚠️ 注意: 一个常见误区:D 太强会导致 G 训练崩溃。当 D 很容易达到 100% 准确时,log(1 - D(G(z))) 接近 0,G 拿到的梯度趋近 0。解决方案:① 用非饱和损失 -log D(G(z)) 替代 log(1 - D(G(z)));② 限制 D 的容量(更少层 / 谱归一化);③ 用 Wasserstein 距离替换 JS 散度。
6.3 GAN 训练技巧
GAN 训练以"难以稳定"著称——它不是一个普通的优化问题,而是 minimax 博弈,损失函数曲线和模型性能的关联很弱。下面是工业界与学术界长期沉淀的实用技巧。
6.3.1 缓解模式崩溃(Mode Collapse)
【现象】
模式崩溃指生成器只生成数据分布中的少数几种模式(如人脸 GAN 只会生成一两张脸,反复出现)。原因是 G 找到了一个能"骗过" D 的"局部最优解",于是停止探索其他模式。
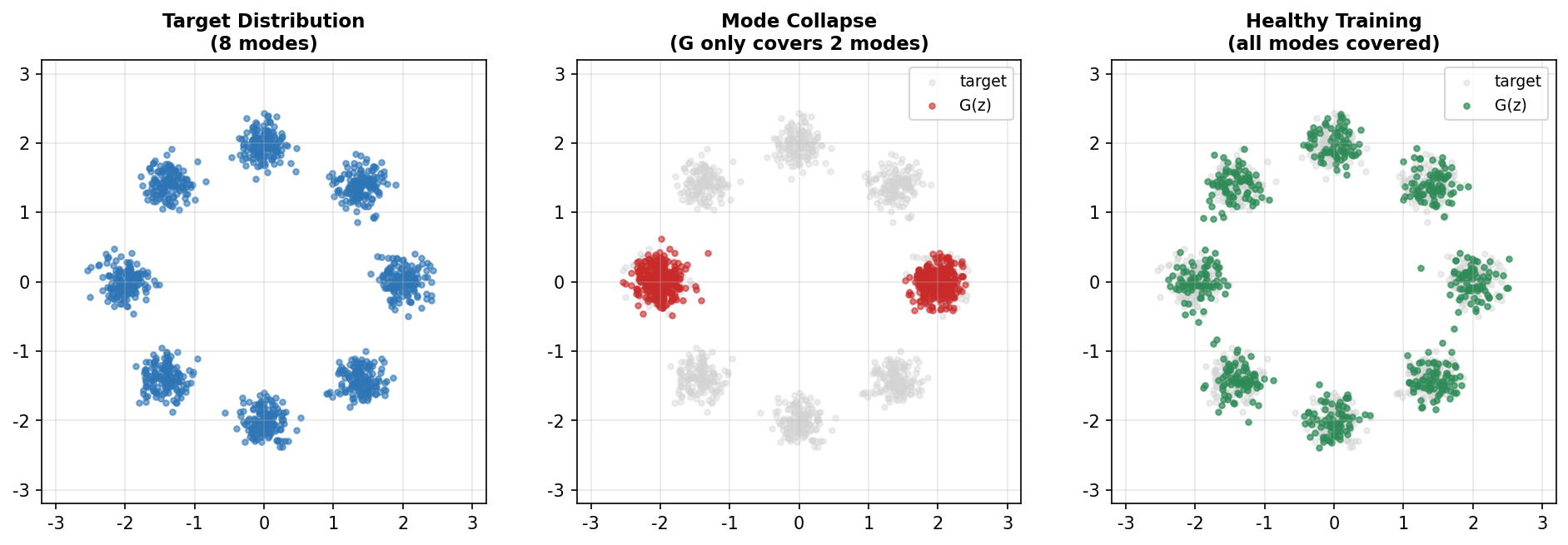
图6-4 模式崩溃:G 仅覆盖目标分布的少数几个模式
【缓解方法】
- Minibatch Discrimination:在 D 中引入一个层,让 D 能"看到"同一 batch 中其他样本的统计信息,从而惩罚 G 生成相互雷同的样本。
- Unrolled GAN:训练 G 时,让它考虑 D 未来 K 步的更新,避免被 D 的瞬时弱点利用。
- PacGAN:把 D 的输入改成 m 个样本的串联,从而让 D 能感知样本多样性。
- WGAN:换用 Wasserstein 距离作为目标,从根本上改善梯度信号(见 6.3.3)。
6.3.2 谱归一化与 1-Lipschitz 约束
现代 GAN 训练几乎默认使用谱归一化(Spectral Normalization, SN):把每层权重矩阵 W 替换为 W / σ(W),其中 σ(W) 是 W 的最大奇异值(用幂迭代估计,几乎不增加计算)。它使 D 的 Lipschitz 常数被约束在 1,从而稳定训练。
# PyTorch 一行启用谱归一化
import torch.nn.utils as utils
self.conv = utils.spectral_norm(nn.Conv2d(in_c, out_c, 4, 2, 1))
6.3.3 Wasserstein 距离与梯度惩罚(WGAN-GP)
【为什么要用 Wasserstein 距离】
原始 GAN 用 JS 散度衡量 p_g 和 p_data 的差异,但当两个分布的"支撑集"不重叠时(高维分布大概率如此),JS 散度恒为 log2,梯度几乎为 0——这就是 GAN 训练初期"D 太强 G 学不动"的根源。
Wasserstein 距离(推土机距离)衡量"把一个分布搬成另一个分布需要的最小代价",即使两个分布无重叠,它也能给出一个有意义的距离值,因此提供平滑的梯度。
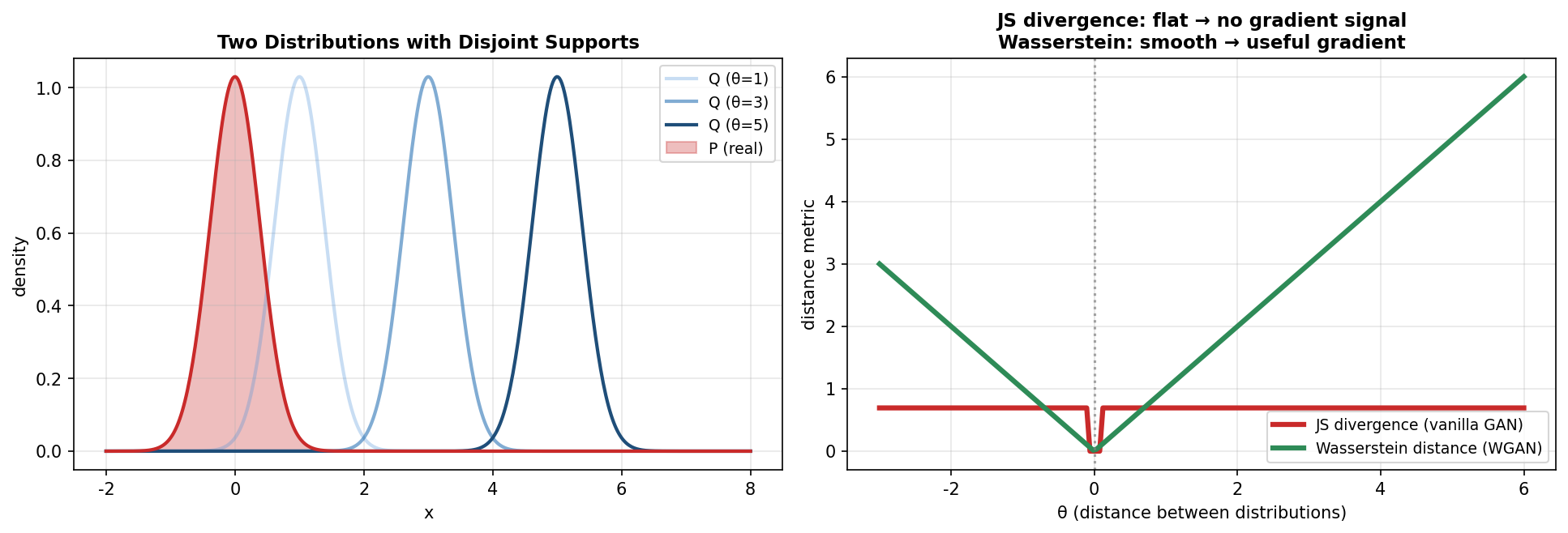
图6-5 JS 散度(不重叠时无梯度) vs Wasserstein 距离(处处可导)
【WGAN 损失】
L_D = E_{x~p_data}[D(x)] - E_{z~p_z}[D(G(z))]
L_G = -E_{z~p_z}[D(G(z))]
其中 D 不再输出概率(无 sigmoid),而是一个标量 critic(评分器)。为了让 Wasserstein 距离的对偶形式成立,D 必须是 1-Lipschitz 的。原始 WGAN 用"权重裁剪"实现(粗暴且效果差),WGAN-GP 改用"梯度惩罚":
L_D += λ · E_{x̂}[(‖∇_{x̂} D(x̂)‖_2 - 1)²]
其中 x̂ 是真实样本 x 和生成样本 G(z) 的随机线性插值,λ 通常取 10。WGAN-GP 是目前最稳健的 GAN 训练方案之一。
6.3.4 双时间尺度更新规则(TTUR)
传统做法是 G 和 D 使用相同的学习率,并且每 step D 多更新 k 次(如 k=5)。TTUR(Two Time-scale Update Rule)证明:让 D 的学习率比 G 大(如 D=4e-4, G=1e-4),两者均每 step 更新 1 次,能更快收敛到纳什均衡,并提升 FID。这是 BigGAN、StyleGAN 等大模型的标准做法。
6.3.5 标签平滑与输入噪声
- One-sided label smoothing:把"真实样本"的标签从 1.0 改为 0.9(不要改 fake 的 0.0),防止 D 输出过于自信,对应缓解 G 的梯度消失。
- 给 D 的输入加上高斯噪声(instance noise):在训练初期给真实图像和生成图像都加上随机噪声,强制两个分布有重叠,从而让 D 提供有效梯度;随训练进行逐渐衰减噪声方差。
6.3.6 特征匹配与 Perceptual Loss
改变 G 的目标:不再仅让 D(G(z)) 接近 1,而是让 G(z) 在 D 中间层的特征激活均值接近真实样本:
L_FM = ‖E_x[f(x)] - E_z[f(G(z))]‖²₂
这种方式比单纯优化 D 的最终输出更稳定,特别适合半监督 GAN。另一相关技巧是 Perceptual Loss:使用预训练 VGG 的中间层作为"语义距离"度量,常用于图像翻译和超分辨率。
6.3.7 评价指标:IS、FID、KID
指标 | 原理 | 取值方向 | 局限 |
IS (Inception Score) | 通过 Inception V3 计算 p(y|x) 的清晰度和 p(y) 的多样性 | 越大越好 | 依赖 ImageNet 类别;对模式崩溃不敏感 |
FID (Fréchet Inception Distance) | 比较真实和生成图像在 Inception 特征空间的均值/协方差差异 | 越小越好 | 需要大量样本估计;偏向高斯假设 |
KID (Kernel Inception Distance) | 用核函数估计 Inception 特征差异,无偏估计 | 越小越好 | 小样本下也可靠;计算稍慢 |
LPIPS | 基于 AlexNet/VGG 特征的感知相似度 | 越小越相似 | 需配对样本;用于图像翻译 |
6.3.8 训练技巧速查表
问题 | 推荐方案 |
训练发散 / Loss 爆炸 | 降低学习率;使用 SN + WGAN-GP;检查 BN/初始化 |
模式崩溃 | WGAN-GP;Minibatch Discrimination;增大隐变量维度 |
D 太强 G 学不动 | 非饱和损失 -log D(G(z));标签平滑;input noise;用 WGAN |
生成图像模糊 | 增加 G 容量;用 Perceptual Loss;换为 StyleGAN 架构 |
棋盘格伪影 | kernel_size 整除 stride;或换 Upsample+Conv |
训练不稳定 / FID 波动大 | TTUR;EMA 平均 G 权重;增大 batch;谱归一化 |
类别条件生成不准 | Projection Discriminator;class-conditional BN |
💡 提示: "GAN tricks bag"经典参考:① Soumith Chintala 的 ganhacks(github.com/soumith/ganhacks);② Salimans et al. 2016 "Improved Techniques for Training GANs";③ Gulrajani et al. 2017 "Improved Training of Wasserstein GANs";④ Brock et al. 2018 "Large Scale GAN Training (BigGAN)"。
第七章 超参数调整
深度学习模型的性能高度依赖超参数的选择。同一份代码、同一个数据集,仅仅是学习率从 1e-3 改成 1e-4,最终精度可能差 5 个百分点;batch size 翻倍配上线性 LR 缩放,可能在收敛速度上差几倍。本章系统梳理超参数的分类、调优顺序、自动化搜索方法,以及"如何用好预训练模型"这一工业界关键技能。
7.1 神经网络中包含哪些超参数?
超参数(Hyperparameter)是训练前需要人为设定、训练过程中不通过梯度下降更新的参数。区别于模型参数(权重 W、偏置 b 等可学习参数)。常见超参数可分为以下几类:
类别 | 具体超参数 | 典型取值范围 |
优化器相关 | 学习率 lr、动量 momentum、Adam 的 β1/β2/ε、weight decay | lr∈[1e-5, 1e-1],β1=0.9,β2=0.999,wd∈[0, 1e-2] |
批训练相关 | batch size、epoch 数、梯度累积步数 | bs∈{16, 32, 64, ..., 1024+},epoch∈{10, 100, 1000} |
学习率调度 | warmup steps、scheduler 类型(cosine/step/linear)、最小 lr | warmup∈{500, 1000, 10000},cosine 最常用 |
网络结构 | 层数、每层通道数/隐藏维度、卷积核大小、stride、padding | 深度 5~200,宽度 32~2048 |
正则化 | dropout 概率、L2 系数、label smoothing、mixup α | p∈[0.0, 0.5],α∈[0.1, 0.4] |
归一化 | BN/LN/GN 等的选择、momentum、ε | BN momentum=0.1,ε=1e-5 |
数据增强 | 增强种类(flip/crop/color jitter/mixup/cutmix)和强度 | 任务相关 |
初始化 | 权重初始化方法(Xavier/Kaiming/正交)、偏置初值 | 配套激活函数选择 |
损失函数 | 损失类型、辅助损失权重、focal loss 的 γ | γ=2 为经典值 |
📌 备注: 不要把架构超参数(比如"用 ResNet 还是 Transformer")和数值超参数混在一起搜索——前者属于"模型设计",后者属于"训练配置",二者的搜索预算和方法完全不同。
7.2 为什么要进行超参数调优?
从三个角度回答:
① 模型表达能力的释放
同一个网络结构,超参数不同会让模型处于完全不同的工作点:欠拟合(学习率太小、正则太强)、过拟合(学习率合适但 epoch 太多、正则太弱)、不收敛(学习率过大)、收敛慢(batch 太大、没有 warmup)。调优本质上是把模型推到"恰好饱和但未过拟合"的最佳工作点。
② 数据集和任务差异
在 ImageNet 上 SOTA 的超参数(如 lr=0.1, bs=256, SGD+momentum)直接用到自己的 5000 张图像数据集上,大概率会发散。数据规模、类别数、噪声水平、长尾程度都会影响最佳超参数。
③ 计算资源约束
工业部署常面临"用更小的模型 / 更少的训练时间达到同样精度"的压力。超参数调优能在不改架构的前提下,把训练时间缩短 2~5 倍(如启用 OneCycleLR + LARS + 大 batch)。
7.3 超参数的重要性顺序
工程经验上的优先级大致如下(从最重要到次要):
优先级 | 超参数 | 理由 / 调节策略 |
★★★★★ 第一档 | 学习率 lr | 影响最大且最敏感。建议先用 LR Range Test 找到上限,再用 cosine/OneCycle 调度。每个新任务的第一件事就是调 lr。 |
★★★★ 第二档 | batch size、优化器选择 | bs 与 lr 联动(线性缩放规则)。小数据集 / 不熟任务用 Adam,大规模 vision 任务用 SGD+momentum 通常更好。 |
★★★ 第三档 | 网络结构(层数 / 宽度)、weight decay、dropout | 架构超参数搜索代价高,先用一个已验证的结构(ResNet50、ViT-B 等)。wd 推荐 1e-4 起步,dropout 视任务而定。 |
★★ 第四档 | LR warmup、scheduler 细节、数据增强组合 | 相对调好基础后再 fine-tune。增强组合对 vision 任务影响显著。 |
★ 第五档 | Adam 的 β1/β2、BN momentum、ε | 一般用默认值即可,除非有特殊原因。改动收益小、容易引入 bug。 |
🔑 要点: 一条经验法则:80% 的精度提升来自学习率和 batch size 的合适配置,剩下的来自结构和正则化。初学者最容易犯的错误是盯着 dropout、β1 反复调,却忽略了 lr 选错一个数量级。
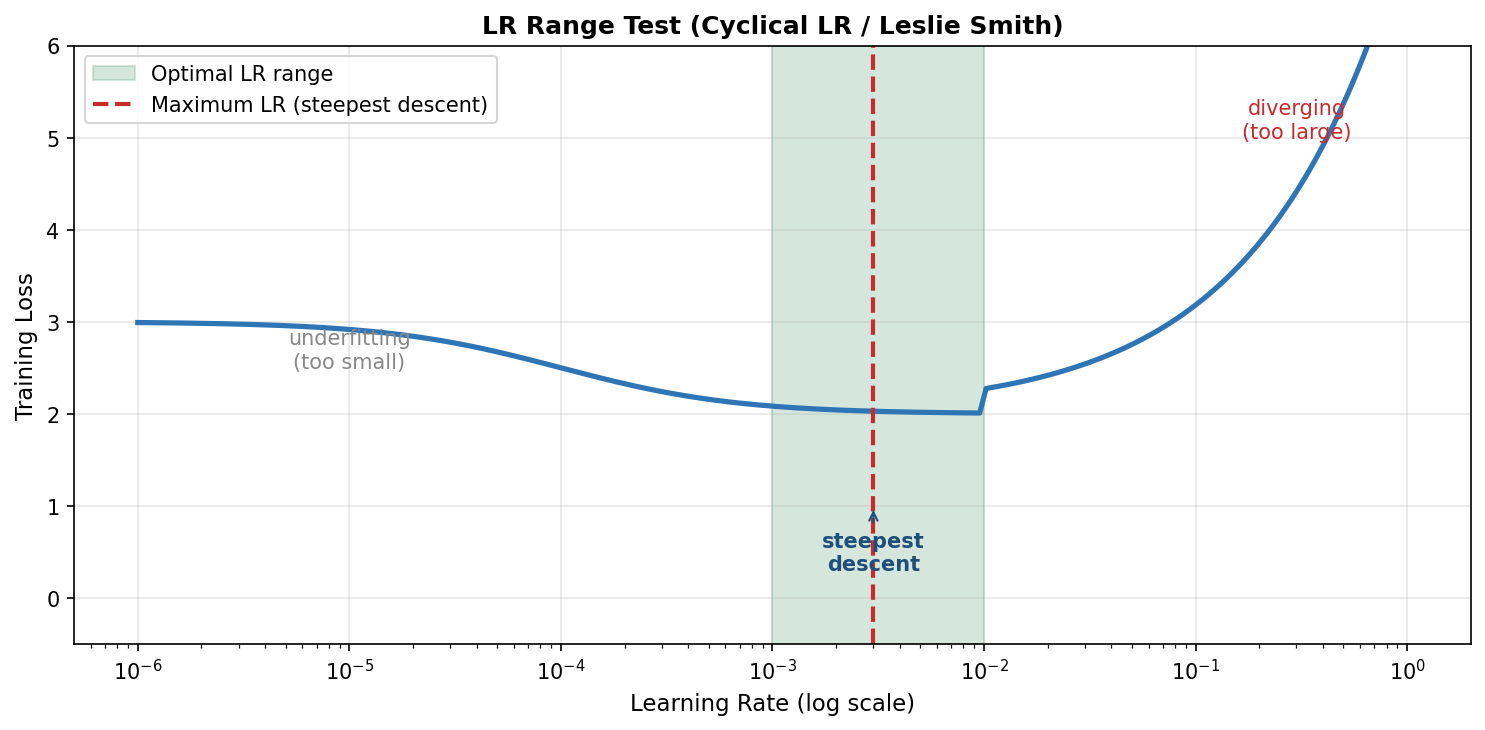
图7-1 LR Range Test:从 1e-6 线性增大 lr 训练,记录 loss 曲线,找到最佳学习率上限
7.4 极端批样本数量下,如何训练网络?
"极端 batch size"分两种情况:① 显存不足导致 batch 很小(如 bs=2~4,常见于检测、分割、高分辨率任务);② 多机多卡下 batch 极大(如 bs=8192~32768,用于加速训练)。两者的应对策略截然不同。
7.4.1 batch 极小(显存受限)
【主要问题】
- 梯度噪声大,训练不稳定。
- BatchNorm 统计量估计不准(bs<8 时尤其严重),导致训练-测试分布不匹配。
- 每个 step 利用率低,整体训练时间长。
【解决方案】
- 梯度累积(Gradient Accumulation):累积 N 个小 batch 的梯度再更新一次参数,等效大 batch 训练。代码上只需要 loss.backward() 多次后再 optimizer.step()。
- 使用 GroupNorm 或 LayerNorm 替代 BatchNorm。GN 对 batch size 不敏感,在检测/分割中(bs 常为 1~4)几乎总是优于 BN。
- 使用 SyncBN(同步 BN):在多卡场景下把所有卡上的 batch 统计量合并计算,等效增大 BN 的有效 batch。
- 混合精度训练(AMP / fp16):节省一半显存,从而把 batch 翻倍。
- 梯度检查点(Gradient Checkpointing):用计算换显存,能把 batch 提高 2~4 倍。
7.4.2 batch 极大(分布式加速)
【主要问题】
- 大 batch 减少梯度噪声,泛化能力下降(落入"sharp minima")。
- 达到相同精度需要的 epoch 数显著增加。
- 训练初期容易发散。
【解决方案】
- 线性 LR 缩放规则(Goyal et al. 2017, Facebook):bs 扩大 k 倍,lr 也扩大 k 倍。该规则在 bs ≤ 8K 内有效。
- LR Warmup:训练初期前 5~10 个 epoch 从 lr/k 线性升到目标 lr,避免大 lr 一上来就发散。
- LARS / LAMB 优化器:对每层权重单独计算"信任比"(trust ratio),缓解大 batch 下不同层学习率不匹配的问题。LARS 用于 SGD 系列(ResNet 等),LAMB 用于 Adam 系列(BERT 等)。BERT 训练把时间从 3 天压缩到 76 分钟,靠的就是 LAMB + bs=32K。
- 数据并行 + 梯度同步(All-Reduce):用 NCCL/Horovod/PyTorch DDP 实现。注意大 batch 下的"learning rate cooldown"也很关键。
场景 | batch size | 核心配置 |
小数据集分类 | 32~128 | Adam, lr=1e-3, cosine annealing |
ImageNet ResNet50 | 256(单机8卡) | SGD+momentum 0.9, lr=0.1, wd=1e-4 |
ImageNet ResNet50(大batch) | 8192 | SGD+LARS, lr=3.2(线性缩放), warmup=5 epoch |
BERT 预训练 | 32768 | LAMB, lr=1e-2, warmup=1% steps |
目标检测(COCO) | 2~16 | SGD+momentum, GroupNorm 替代 BN, lr=0.02 |
语义分割(高分辨率) | 4~8 | SyncBN+梯度累积, AdamW, lr=6e-5(如 SegFormer) |
7.5 合理使用预训练网络
在工业界,几乎所有 vision 和 NLP 任务的标准流程都是"加载预训练权重 → 在下游任务上微调"。预训练模型能利用大规模数据(ImageNet、LAION、Wikipedia 等)学到的通用特征,让下游任务用更少数据、更短时间达到更高精度。本节系统讨论微调的方方面面。
7.5.1 什么是微调(fine-tune)?
微调是迁移学习的一种典型实现:把一个在源任务(如 ImageNet 1000 类分类)上预训练好的模型,作为初始化权重,在目标任务(如猫狗二分类、医学影像分割)上继续训练。与"从零开始训练(train from scratch)"相比,微调能:
- 显著减少所需训练数据量(从万级降到千级甚至百级)。
- 缩短训练时间(往往只需几个 epoch 即可收敛)。
- 提升最终精度,尤其在小数据集上效果显著。
- 降低过拟合风险(预训练特征本身有一定正则化作用)。
本质上,微调把模型的优化起点从"随机噪声"挪到了"已经学到良好低层特征"的位置,使其更容易找到目标任务的好解。
7.5.2 微调有哪些不同方法?
方法 | 做法 | 适用场景 |
特征提取(Linear Probing) | 冻结全部预训练参数,只训练新加的分类头 | 数据量极少(<1k);任务与预训练高度相似;快速 baseline |
浅层微调 | 冻结底层若干 block,只微调高层 + 分类头 | 中等数据量;任务与预训练较相似;显存有限 |
全网络微调 | 所有参数都参与训练,但用较小学习率 | 数据量充足(>10k);任务与预训练有一定差异 |
分层学习率(Discriminative LR) | 不同层用不同 lr:底层 lr 小,顶层 lr 大 | 需要更精细控制(fastai、ULMFiT 风格);NLP 任务常用 |
Adapter / LoRA | 插入小的可训练模块,冻结主网络 | 大模型(LLM、ViT-L);多任务部署;参数高效微调 |
Prompt Tuning / Prefix Tuning | 只学习输入端的连续提示向量 | 超大规模 LLM;每任务参数 < 1% |
# PyTorch 典型微调:冻结底层 + 替换分类头
import torchvision.models as models
model = models.resnet50(weights="IMAGENET1K_V2")
# 冻结所有层
for p in model.parameters():
p.requires_grad = False
# 替换最后的全连接(自动 requires_grad=True)
model.fc = nn.Linear(model.fc.in_features, num_classes)
# 只优化未冻结的参数
optimizer = torch.optim.Adam(
filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)
7.5.3 微调先冻结底层、训练顶层的原因?
【特征层级理论】
CNN 的特征学习呈现明显的层级性(Zeiler & Fergus, 2014 的可视化工作):
- 浅层(第 1-2 层):学到通用的低层特征(边缘、颜色块、纹理),这些特征在任何视觉任务中都通用。
- 中层(第 3-4 层):学到部件级特征(眼睛、轮子、纹路图案),具有一定的领域通用性。
- 深层(最后几层):学到任务特定的高层语义("猫脸"、"狗的姿态"),与具体类别强相关。
【因此微调策略是:】
- 底层(通用特征层):冻结或用极小学习率(如 1e-5)。它们已经"学得很好",在小数据集上继续训练反而会破坏这些通用特征(catastrophic forgetting)。
- 中层:可适度微调,学习率介于底层和顶层之间。
- 顶层 + 分类头:完全替换(因为类别数变了)并用较大学习率(如 1e-3)训练。它们承担"把通用特征映射到新任务标签空间"的核心职责。
⚠️ 注意: 错误做法警示:① 全网络用相同的大学习率(如 1e-2)微调——会"震碎"预训练权重,反而不如 train from scratch;② 完全不冻结也不调小学习率——容易过拟合小数据集。
7.5.4 不同数据集特性下如何微调?
这是一个经典的"2×2 决策矩阵",按"数据集规模"和"与预训练数据的相似度"两个维度划分。
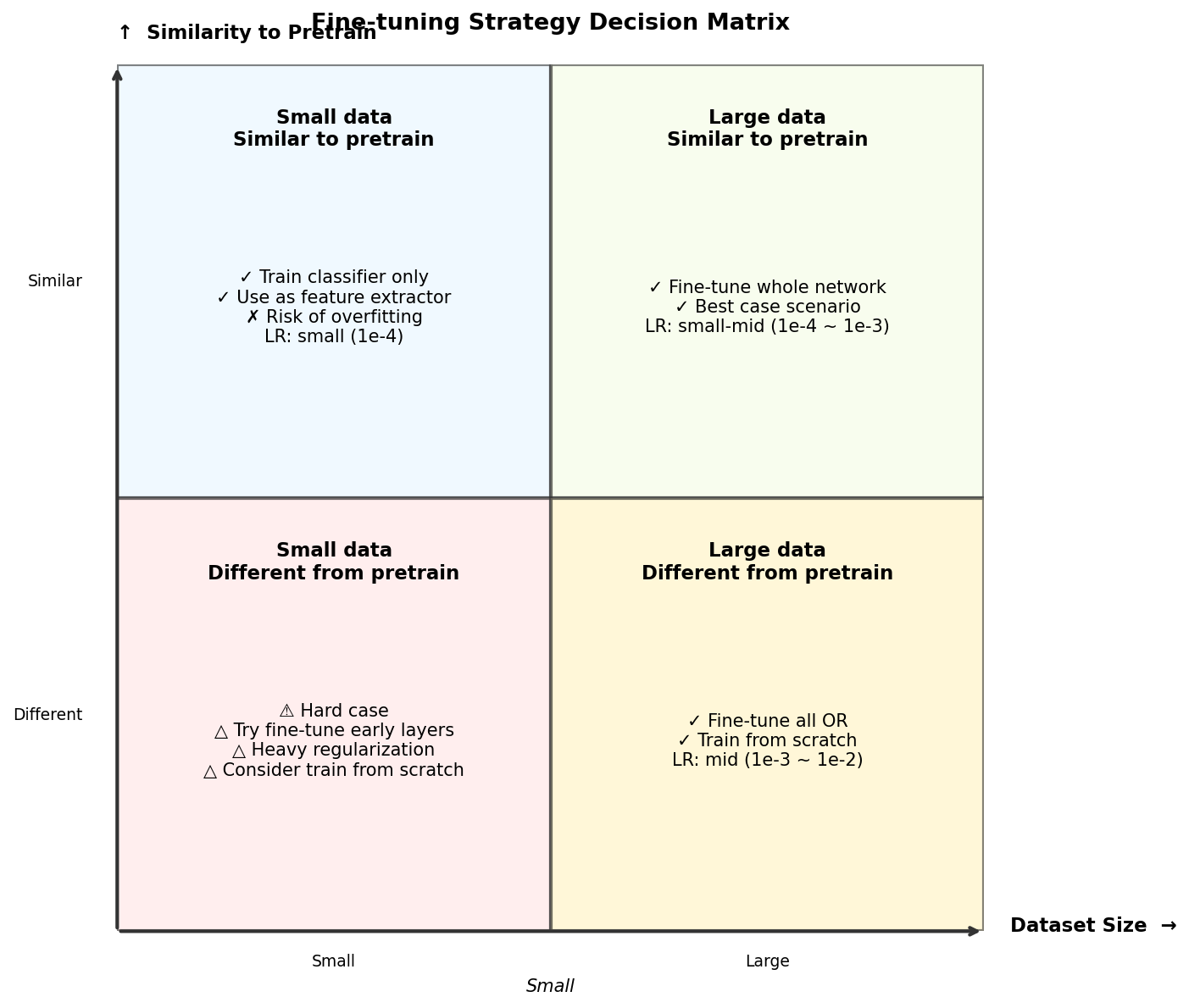
图7-2 微调策略决策矩阵:根据数据规模和相似度选择策略
象限 | 场景 | 推荐策略 |
Q1:数据多+相似 | 如:ImageNet 预训练 → 自建图像分类(数十类) | 全网络微调;lr 中等(1e-4 ~ 1e-3);这是最理想的情况 |
Q2:数据少+相似 | 如:ImageNet → 猫狗分类(1000 张) | 冻结底层,只训练顶层;甚至直接 Linear Probing;强正则化(dropout、mixup、增强)防止过拟合 |
Q3:数据少+不同 | 如:ImageNet → 医学 X 光分类(500 张) | 最棘手的情况;尝试微调早期/中期层(底层通用特征仍有用);考虑半监督 / self-supervised 预训练替代 ImageNet 权重 |
Q4:数据多+不同 | 如:ImageNet → 卫星图像分割(10 万张) | 可以全网络微调,但 lr 略大;也可以考虑 train from scratch,甚至先在领域数据上做 self-supervised 预训练 |
7.5.5 目标检测中使用预训练模型的优劣?
【优势】
- 收敛速度快:用 ImageNet 预训练的 backbone 启动 COCO 检测训练,收敛 epoch 数比 from scratch 少 4~6 倍。
- 小数据集精度更高:当检测数据集只有数千张图像时,预训练几乎是必须的。
- 降低硬件门槛:预训练初始化让模型对学习率、初始化等超参数更鲁棒。
【劣势】
- 架构受限:必须使用与预训练对齐的 backbone(ResNet、Swin 等),无法自由设计新结构。
- 域差距问题:ImageNet 是 RGB 自然图像,与 SAR、医学影像、深度图等差异大时,预训练特征可能反而是"坏先验"。
- 引入归纳偏置不可控:预训练模型对某些类别(如 ImageNet 中的犬科)有偏向,在长尾或类别极不平衡数据集上可能放大偏差。
- 训练范式被绑定:BN 的统计量来自 ImageNet 分布,迁移到新数据集时需要特别处理(如 frozen BN)。
7.5.6 目标检测中如何从零开始训练(train from scratch)?
【背景】
何凯明等人在 "Rethinking ImageNet Pre-training"(2018)中证明:当训练数据充足、训练时间足够时,COCO 检测器从零开始训练能达到与预训练相当甚至略优的精度。这打破了"必须 ImageNet 预训练"的迷信。
【关键技术】
- Group Normalization 或 SyncBN:替代 frozen BN,因为 batch size 在检测任务中通常很小。GN 完全不依赖 batch 统计量,是 from scratch 训练的关键组件之一。
- 训练更久:from scratch 需要约 3~9 倍的 epoch 数(COCO 从 12 epoch 增至 72 epoch)。
- 正则化加强:mixup、cutmix、强数据增强、更大的 weight decay。
- 合理的初始化:He / Kaiming 初始化对深网络至关重要。
【典型代表】
- DSOD(2017):第一个论证小数据集也能 from scratch 训练检测器的工作,提出 deep supervision 等技巧。
- Rethinking ImageNet Pre-training(He et al., 2018):在 COCO 上系统对比,证明 from scratch 可行。
- CenterNet / FCOS / DETR:现代 anchor-free 检测器,对预训练依赖度有所降低。
💡 提示: 工程结论:① 数据量小 / 训练资源有限 → 用预训练(成本/收益最佳);② 数据量大(>10 万) / 域差异大 → 考虑 from scratch;③ 折中方案:在领域内数据上做 self-supervised 预训练(如 MAE、SimCLR),再微调,这是当前的主流范式。
7.6 自动化超参数搜索方法有哪些?
随着模型复杂度增加,手工调参的代价越来越大。自动化超参数优化(HPO/AutoML)工具能在给定预算下系统地搜索超参数空间。
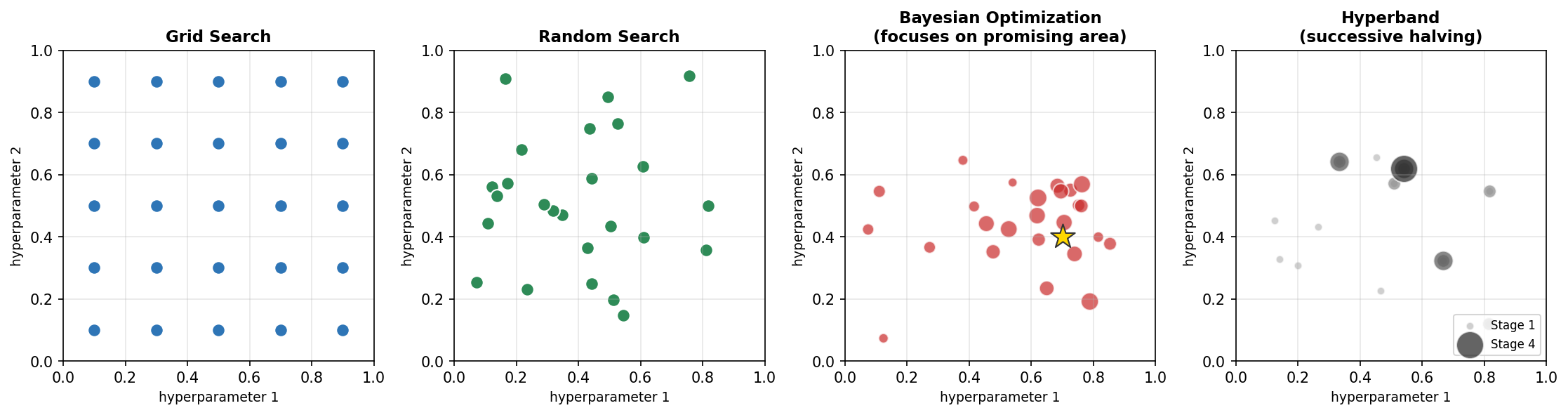
图7-3 四种主流超参数搜索方法的采样模式对比
7.6.1 网格搜索(Grid Search)
对每个超参数定义一个离散的候选值集合,遍历所有组合。例如 lr ∈ {1e-4, 1e-3, 1e-2}, bs ∈ {32, 64, 128} 共 9 个组合。
- 优点:实现简单;可完整覆盖空间;易并行;结果可复现。
- 缺点:维度灾难——超参数个数增加,组合数指数爆炸;对每个维度的采样密度低。
- 适用:超参数 ≤ 3 个的小空间;快速验证 baseline。
7.6.2 随机搜索(Random Search)
从每个超参数的分布中独立随机采样。Bergstra & Bengio (2012) 证明:在相同试验次数下,随机搜索通常优于网格搜索,因为只有少数超参数真正重要,网格搜索把预算浪费在了不重要的维度上。
- 优点:实现简单;对高维空间更友好;易并行。
- 缺点:仍然是无信息搜索,不利用已有评估结果。
- 实践:sklearn.model_selection.RandomizedSearchCV;注意学习率等用对数均匀采样:lr ~ LogUniform(1e-5, 1e-1)。
7.6.3 贝叶斯优化(Bayesian Optimization)
基于高斯过程(GP)或 Tree Parzen Estimator(TPE)等代理模型,从已评估的样本中拟合"超参数→指标"的映射,通过采集函数(如 Expected Improvement, UCB)选择下一个最值得评估的超参数点,在"探索(exploration)"和"利用(exploitation)"间平衡。
- 优点:采样效率高,少量试验即可逼近最优;适合训练昂贵的任务。
- 缺点:串行依赖(下一个点取决于前面所有点);维度增加时高斯过程计算变慢;不利于并行化。
- 实现:Optuna(TPE 默认)、Ax/BoTorch(Meta)、scikit-optimize、Hyperopt。
7.6.4 Hyperband / Successive Halving
核心思想:早期淘汰(early stopping)—— 先用很少的资源(如 1 epoch)评估很多配置,保留 top 1/η,再投入更多资源继续训练,逐轮淘汰,直到只剩最优配置。
- Successive Halving (SHA):单轮逐步减半。
- Hyperband:多次以不同 η 运行 SHA,自动权衡探索宽度和深度。
- 优点:充分利用部分训练曲线的信息,效率远高于随机搜索;天然支持并行。
- 缺点:要求"中间指标能预测最终性能"——对学习率冷启动差的任务(如 transformer warmup)可能误判。
7.6.5 BOHB(Bayesian Optimization + Hyperband)
把贝叶斯优化和 Hyperband 结合:用 Hyperband 决定资源分配,用 BO(基于 TPE)决定采样下一个点。兼顾了"高效利用早期评估"和"贝叶斯采样的信息引导",是 AutoML 的主流方法之一。
7.6.6 Population Based Training(PBT, DeepMind)
维护一个"种群"(如 16 个并行 worker),每个 worker 跑不同超参数。周期性地:① 表现差的 worker 复制表现好的 worker 的权重和超参数;② 对超参数做随机扰动(perturb)。相当于"进化算法 + 边训练边调参"。
- 优点:超参数动态调整(如 lr 随训练阶段自动衰减);适合 RL 等训练曲线波动大的任务。
- 缺点:需要充足的并行资源(一般 ≥ 16 个 worker);实现复杂。
- 典型应用:AlphaStar 训练、Catch-Up Learning,Ray Tune 内置支持。
7.6.7 总结:如何选择 HPO 方法?
场景 | 推荐方法 | 工具 |
超参数 ≤ 3 个,每次训练快 | 网格搜索 | sklearn |
维度 4~10,每次训练几小时 | 随机搜索 / 贝叶斯优化 | Optuna, Hyperopt |
维度 4~10,每次训练 ≥ 1 天 | Hyperband / BOHB | Ray Tune, HpBandSter |
并行资源充足,且训练曲线波动大(如 RL) | PBT | Ray Tune |
超大模型微调(如 LLM) | 人工 + 少量贝叶斯优化 | 业内仍以经验为主 |
💡 提示: 一个实用工作流:① 用 LR Range Test 定下学习率上限;② 用随机搜索粗扫 20 组配置,找到 top-3 配置的"邻域";③ 用贝叶斯优化在邻域内精搜 30 组;④ 在最终模型上用更长 epoch 验证。
—— 全文完 ——
本文档系统梳理了深度学习面试常见的 7 大模块约 100 个问题,从神经网络基础到 GAN 和超参数调优,配合 20+ 张概念示意图。希望能成为读者面试准备和日常工作中的有用参考。技术内容会随研究进展更新,建议结合最新论文与开源代码持续学习。
评论区
使用 GitHub 账号登录后即可评论(由 GitHub Discussions 驱动)